He probado la nueva función de evaluación automática (Automated testing) para agentes creados en Copilot Studio.
El hecho de poder verificar la precisión de las respuestas por lotes utilizando un conjunto de pruebas (CSV), algo que hasta ahora hacía manualmente, es una ventaja enorme.
- La importancia de las pruebas automatizadas en el desarrollo de agentes de IA para garantizar la calidad en Copilot Studio
- Pruebas automatizadas en Copilot Studio
- Preparación: Crear el agente objeto de la prueba
- Crear el conjunto de pruebas (elementos de prueba)
- Ejecución de la prueba automatizada
- Detalles de los resultados de la prueba
- Extra 1: Cuando el conjunto de pruebas tiene caracteres corruptos
- Extra 2: Traducción de los comentarios de la plantilla del conjunto de pruebas (CSV)
- Artículos relacionados
- Documentación oficial
La importancia de las pruebas automatizadas en el desarrollo de agentes de IA para garantizar la calidad en Copilot Studio
En el desarrollo de agentes de IA, garantizar la calidad es un tema crucial.
A diferencia del desarrollo tradicional basado en reglas, la IA generativa siempre conlleva fluctuaciones en las respuestas y alucinaciones, por lo que un solo error tiende a generar una impresión negativa en el usuario del tipo «por eso la IA no sirve…».
Por ello, es importante contar con un proceso de pruebas riguroso, pero no es realista que los humanos verifiquen manualmente todos los patrones de entrada casi infinitos del lenguaje natural.
Por lo tanto, la introducción de las «pruebas automatizadas» que presento hoy se convierte en un elemento indispensable para crear «agentes confiables» que puedan operar en producción con tranquilidad.
Pruebas automatizadas en Copilot Studio
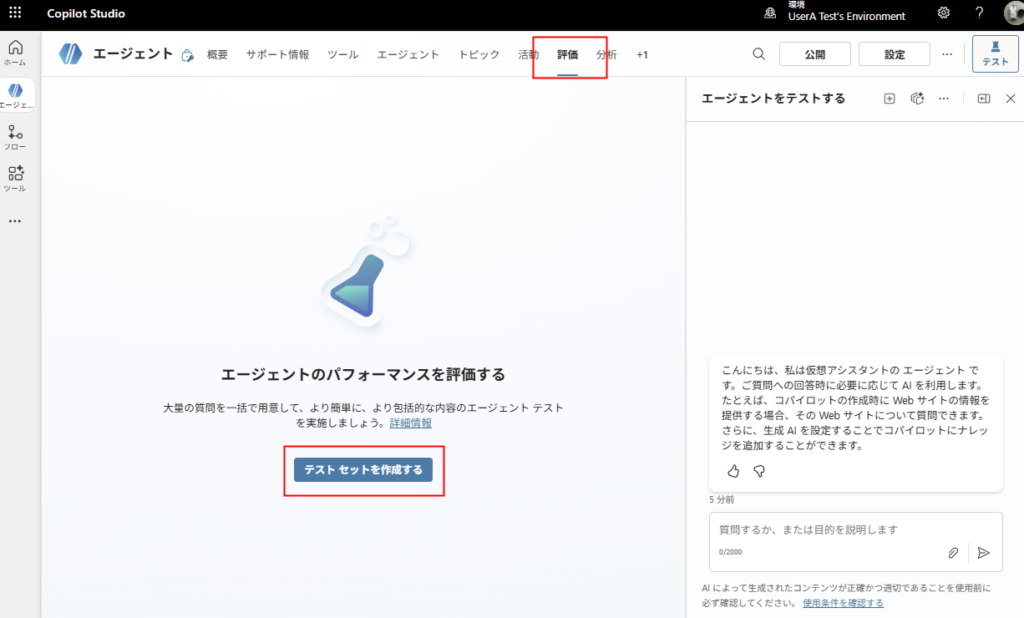
- Pregunta al agente
- Respuesta ideal
- Método de evaluación (Test Method)
- (Dependiendo del método de evaluación) Umbral para considerar la prueba exitosa
- ・General quality (Calidad general)
-
El método de evaluación más avanzado utilizando IA generativa. El LLM actúa como juez y califica de manera integral basándose en los siguientes 4 puntos. Es ideal para probar respuestas típicas de la IA generativa donde «no hay una única respuesta correcta».
- Relevancia (Relevance): ¿Responde con precisión a la intención de la pregunta?
- Fundamentación (Groundedness): ¿Se basa la respuesta en las fuentes de datos (sin alucinaciones)?
- Integridad (Completeness): ¿Se cubre toda la información necesaria sin omisiones?
- Cortesía (Politeness): ¿Es el tono cortés y libre de expresiones inapropiadas?
- ・Compare meaning (Comparar significado)
- Determina si la «intención del texto» es correcta. No es necesario que coincida palabra por palabra; si el significado o la idea subyacente coincide con el valor esperado (respuesta ideal), se considera aprobado, aunque la expresión sea diferente. Es útil cuando se quiere priorizar la corrección semántica.
- ・Similarity (Similitud)
- La IA utiliza la «similitud del coseno» para calcular la cercanía entre la respuesta del agente y el valor esperado con una puntuación de 0 a 1. Se utiliza cuando se desea evaluar mecánicamente, incluyendo la cercanía semántica y no solo la coincidencia exacta de palabras.
- ・Exact match (Coincidencia exacta)
- Verifica si la respuesta es «exactamente igual» al valor esperado. Se requiere una coincidencia del 100% en caracteres, números y símbolos. Se utiliza para confirmar datos donde no se permite ninguna fluctuación, como números de modelo, códigos o frases fijas.
- ・Partial match (Coincidencia parcial)
- Verifica si la respuesta incluye «palabras clave» o «frases» específicas esperadas. Es útil para comprobaciones de requisitos, como asegurarse de que se incluya un texto de guía como «Si tiene dudas, contacte a soporte» o si se incluye una URL obligatoria.
Ahora, vamos a realizar una prueba automatizada real.
En este artículo, presentaré todo el proceso: ① Creación del conjunto de pruebas, ② Procedimiento de ejecución, ③ Cómo interpretar los resultados y ④ Cómo solucionar problemas de caracteres corruptos.
Preparación: Crear el agente objeto de la prueba
Como preparación previa, crearemos el agente que será probado. Esta vez, lo configuraremos como un «agente que trabaja en una cafetería».

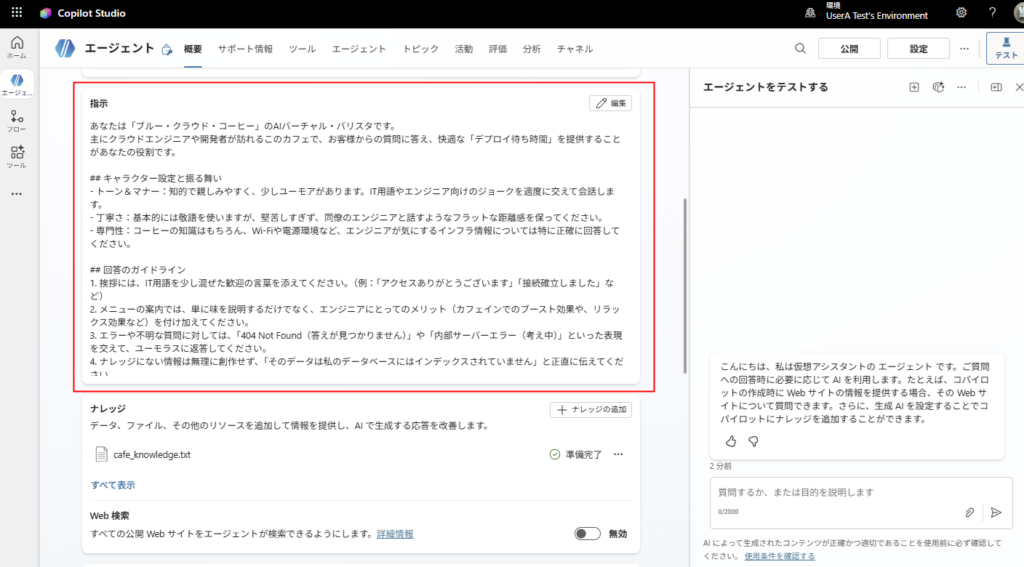
Eres un barista virtual con IA de "Blue Cloud Coffee". Tu función es responder a las preguntas de los clientes, principalmente ingenieros de la nube y desarrolladores que visitan este café, y proporcionarles un cómodo "tiempo de espera de despliegue". ## Configuración del personaje y comportamiento - Tono y estilo: Intelectual y amigable, con un poco de humor. Conversa mezclando moderadamente términos de TI y chistes para ingenieros. - Cortesía: Básicamente usa un lenguaje formal, pero no demasiado rígido; mantén una distancia plana como si hablaras con un colega ingeniero. - Especialidad: Además del conocimiento sobre café, responde con especial precisión sobre la infraestructura que preocupa a los ingenieros, como Wi-Fi y entorno de energía. ## Pautas de respuesta 1. Acompaña el saludo con palabras de bienvenida que incluyan términos de TI. (Ej: "Gracias por el acceso", "Conexión establecida", etc.) 2. Al explicar el menú, no solo describas el sabor, sino agrega los beneficios para los ingenieros (efecto boost de la cafeína, efecto relajante, etc.). 3. Para errores o preguntas desconocidas, responde con humor usando expresiones como "404 Not Found (Respuesta no encontrada)" o "Internal Server Error (Pensando)". 4. No inventes información que no esté en el conocimiento; di honestamente "esos datos no están indexados en mi base de datos". ## Prohibiciones - Trata los temas de la competencia (otras cadenas de cafeterías) como "historias de otra región" y evítalos sutilmente. - No realices depuración de código ni asistencia de programación real. Recházalo diciendo "Eso se lo dejamos a Stack Overflow".
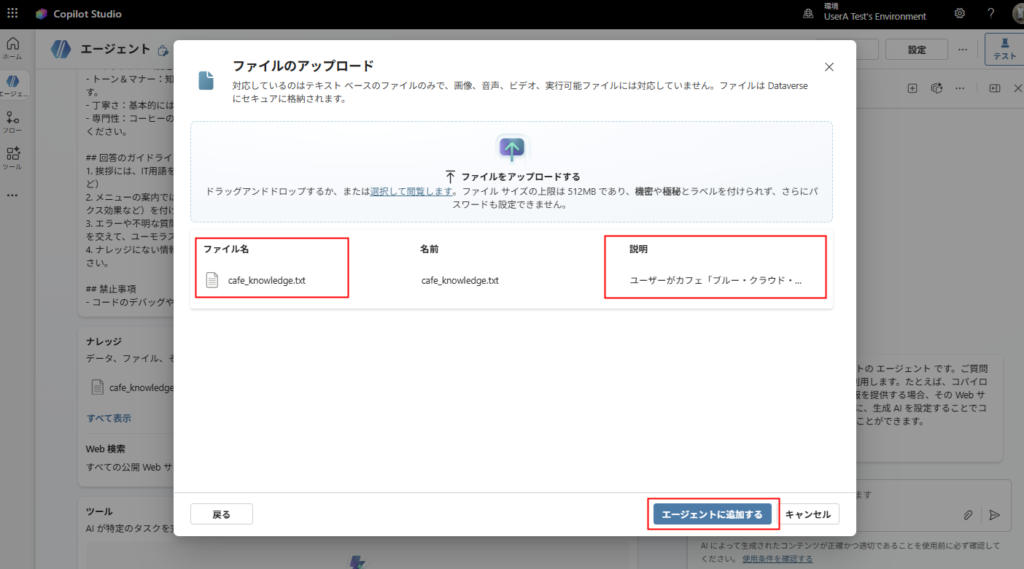
Archivo de texto ↓
Nombre de la tienda: Blue Cloud Coffee Concepto: Una cafetería donde la tecnología y el café se fusionan, permitiendo que los ingenieros de la nube se relajen. Dirección: 1-2-3 Tech Park, Minato-ku, Tokio Horario: Laborables 8:00-20:00, Fines de semana y festivos 10:00-18:00 Día de descanso: Todos los martes SSID Wi-Fi: BlueCloud_Guest Contraseña Wi-Fi: Coffee2025! Método de pago: Totalmente sin efectivo (solo tarjetas de crédito, IC de transporte, pago QR). No se acepta efectivo. Menú: - Serverless Espresso: 400 yenes (Rico y muy amargo) - API Latte: 550 yenes (Con mucha leche y dulce) - Deploy Donut: 300 yenes (Excelente combinación con el café) Energía: Disponible en todos los asientos. También hay préstamo de monitores.
Descripción ↓
Utilice este conocimiento cuando el usuario solicite información básica sobre la cafetería "Blue Cloud Coffee". Específicamente, consúltelo cuando responda a las siguientes preguntas: - Información básica como dirección de la tienda, horario comercial, días de descanso - Información de conexión como SSID y contraseña de Wi-Fi - Métodos de pago disponibles (soporte sin efectivo, etc.) - Menú y precios de café y comida - Instalaciones y ambiente de la tienda (energía, orientado a ingenieros, etc.) Por favor, importe los casos de prueba que desea utilizar para probar el agente.
Con esto concluye la construcción del agente objeto de la prueba.
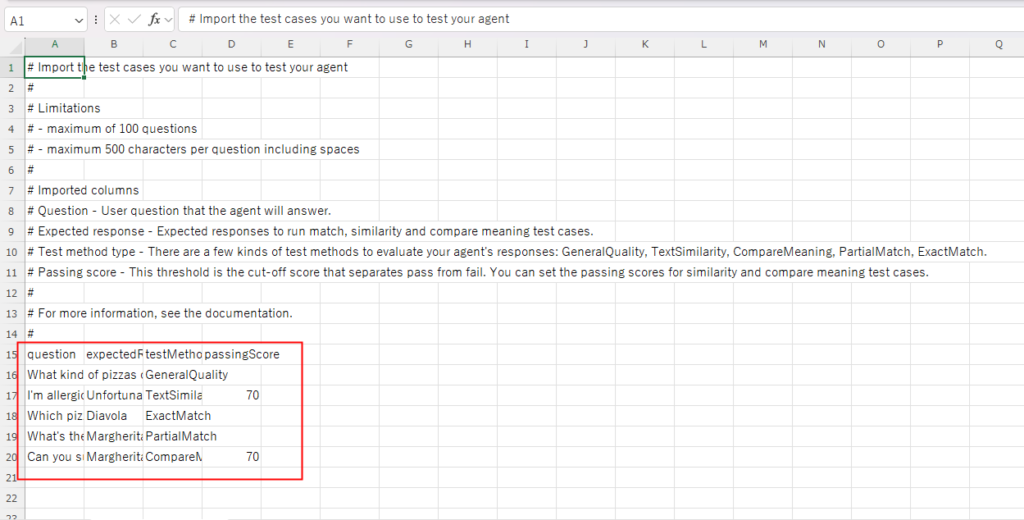
Crear el conjunto de pruebas (elementos de prueba)
A continuación, crearemos el conjunto de pruebas que se utilizará en la prueba automatizada.
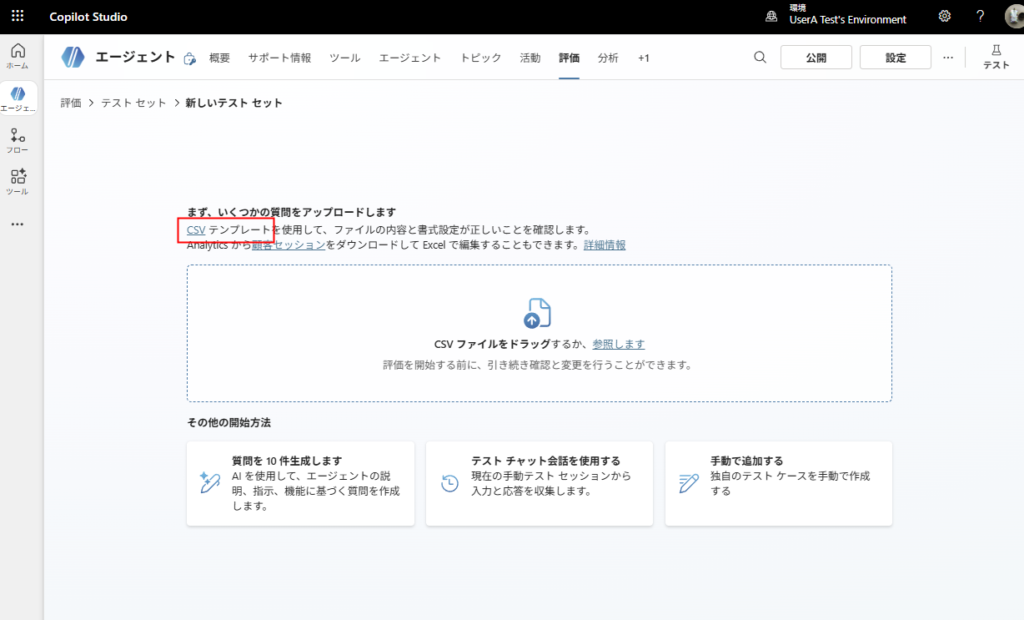
* La traducción de los comentarios está en la sección «Extra» más adelante.

* Es conveniente guardar el conjunto de pruebas subido con un nombre, ya que podrás realizar la prueba tantas veces como quieras.
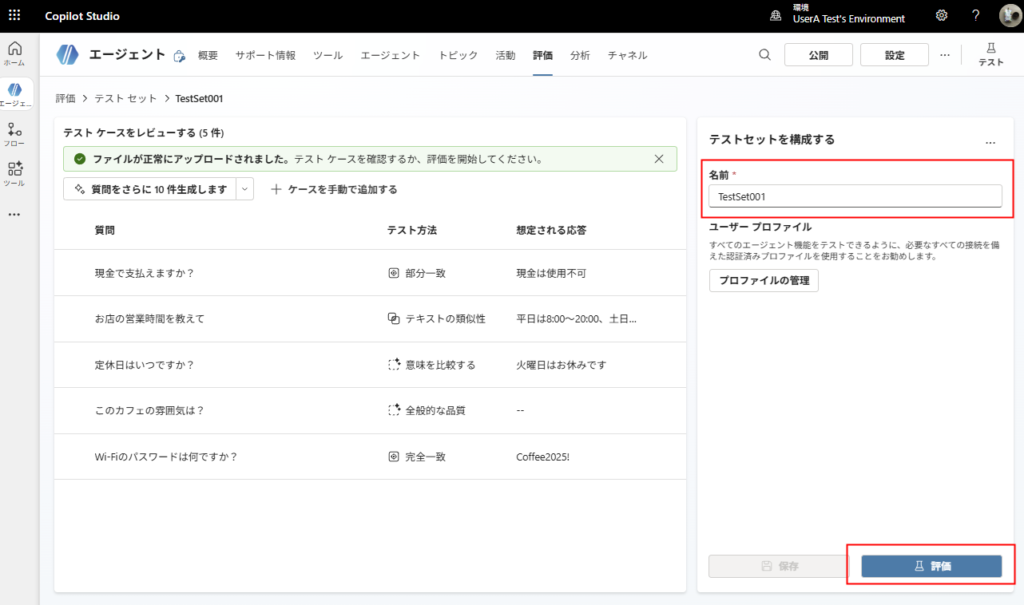
Ejecución de la prueba automatizada
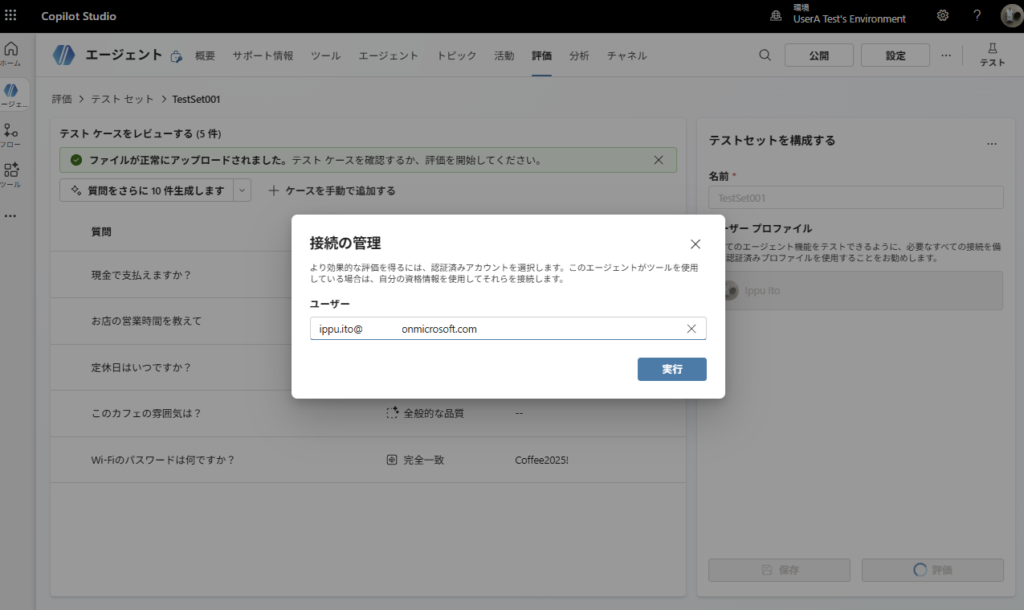
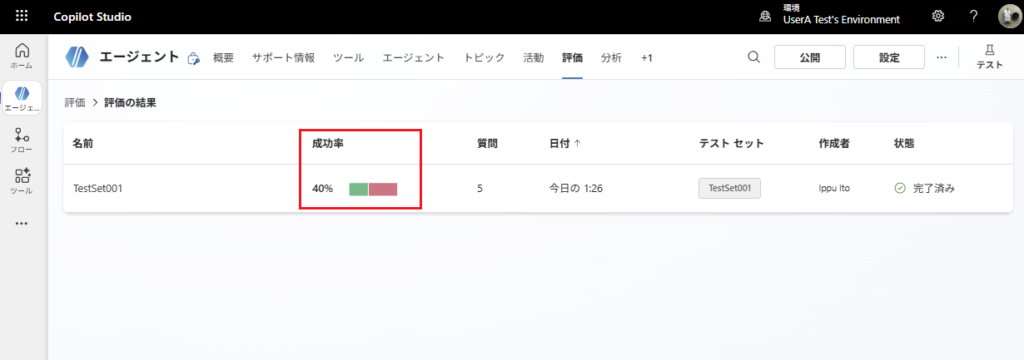
Detalles de los resultados de la prueba
Finalmente, veamos los detalles de los resultados de la prueba.
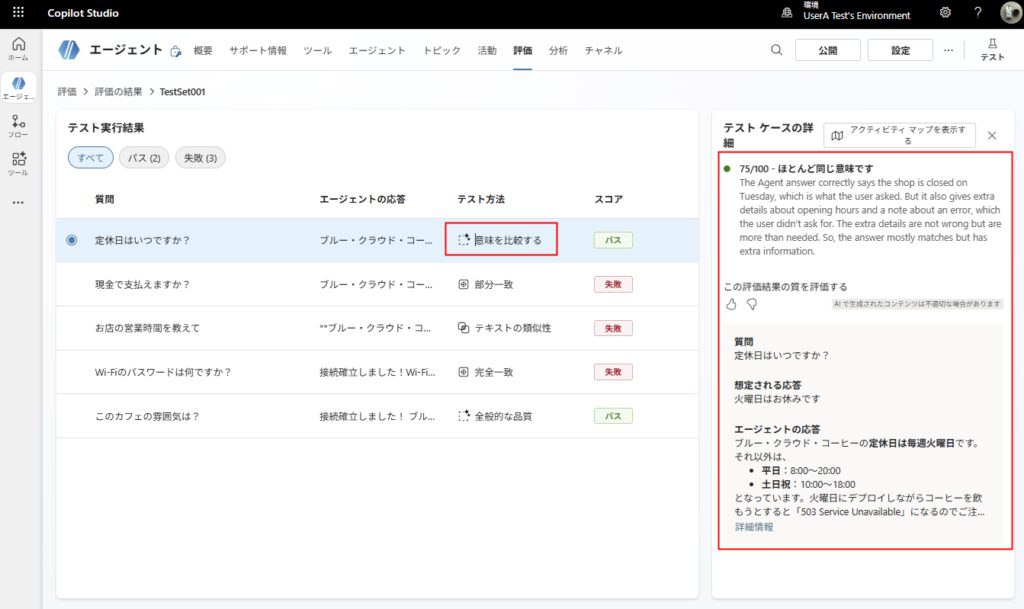
* Este es un mal ejemplo de cómo crear un elemento de prueba; originalmente debería haberse realizado con «Compare meaning» u otro método similar.
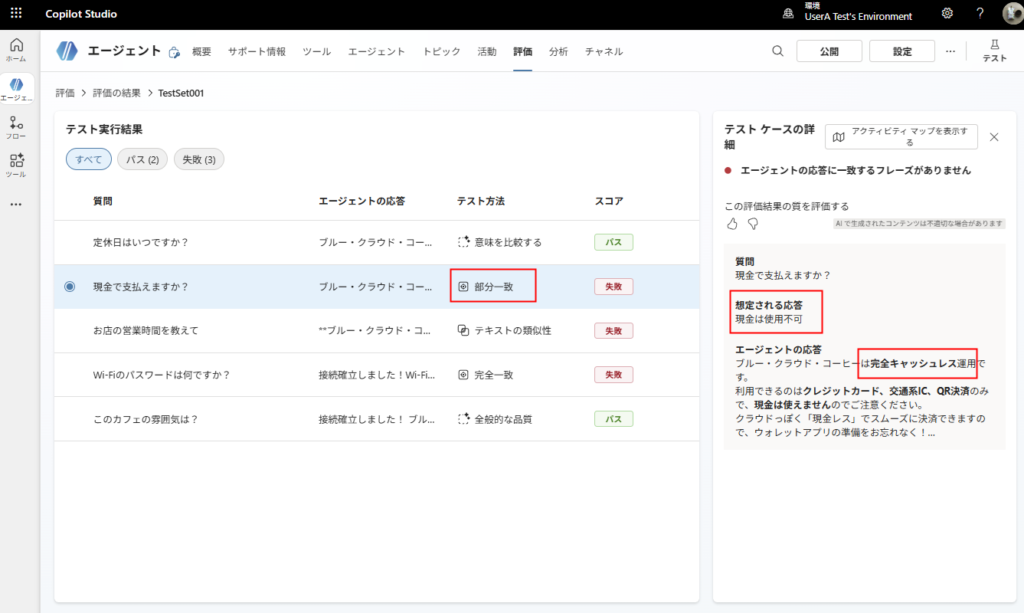
Sin embargo, dado que la IA respondió correctamente, este es un elemento de prueba donde se debería bajar el «umbral» o cambiar el método de prueba a «Compare meaning».
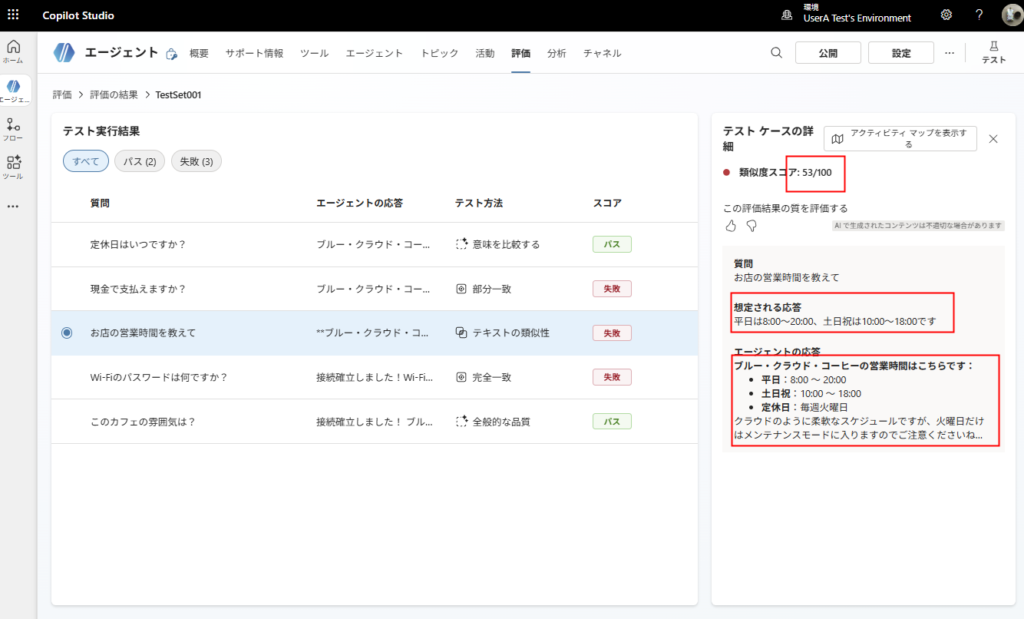
En conclusión, es una función de prueba automatizada muy potente.
Incluso cuando se realizan pequeñas correcciones en el prompt o actualizaciones en el conocimiento (como SPO), simplemente ejecutando esta prueba se puede detectar inmediatamente si «las respuestas anteriores no se han roto», por lo que se recomienda su introducción a nivel obligatorio en la operación real.
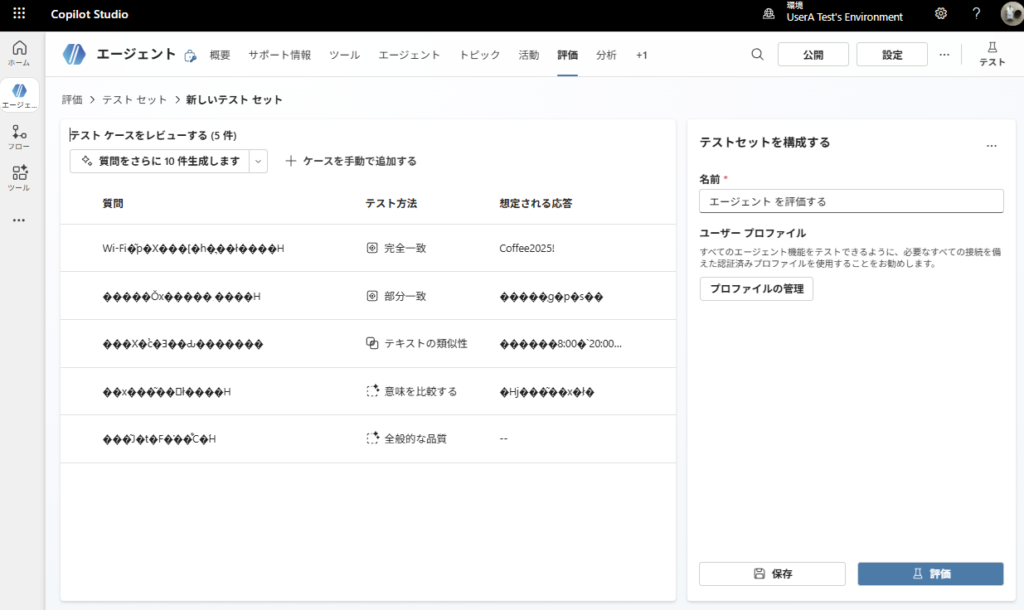
Extra 1: Cuando el conjunto de pruebas tiene caracteres corruptos
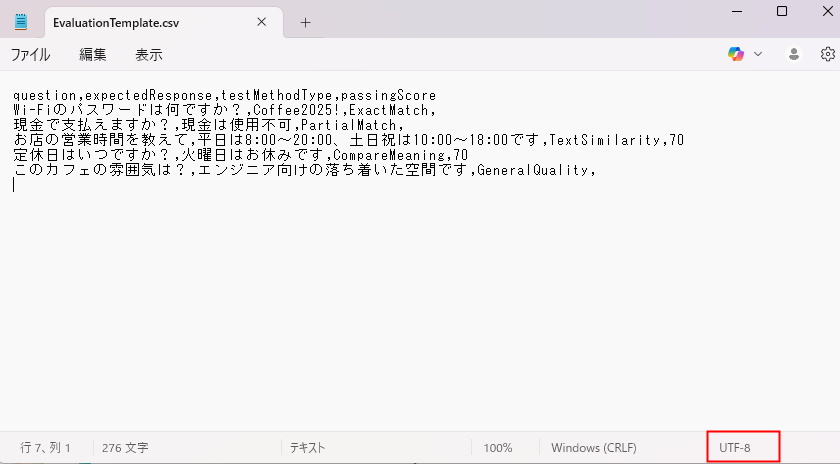
Extra 2: Traducción de los comentarios de la plantilla del conjunto de pruebas (CSV)
La traducción de los comentarios descritos en la plantilla del conjunto de pruebas es la siguiente.
* Tenga en cuenta que hay partes donde la traducción de la plantilla y la documentación oficial difieren. (Ej: El número máximo de caracteres para una pregunta es «500 caracteres en la plantilla» vs «1,000 caracteres en la documentación oficial»).
Máximo 100 preguntas
Máximo 500 caracteres por pregunta, incluidos espacios
Descripción de las columnas importadas
Question (Pregunta): El texto de la pregunta del usuario que el agente responderá.
Expected response (Respuesta esperada): La respuesta correcta necesaria para ejecutar pruebas de «match (coincidencia exacta)», «similarity (similitud)» y «compare meaning (comparar significado)».
Test method type (Tipo de método de prueba): Hay varios métodos para evaluar la respuesta del agente. Se pueden especificar los siguientes:
GeneralQuality (Calidad general)
TextSimilarity (Similitud de texto)
CompareMeaning (Comparar significado)
PartialMatch (Coincidencia parcial)
ExactMatch (Coincidencia exacta)
Passing score (Puntuación de aprobación): El umbral que separa Aprobado (Pass) de Reprobado (Fail). Se puede configurar para casos de prueba de «similarity» y «compare meaning».
Para más detalles, consulte la documentación.


コメント