Following our previous implementation of Naive RAG in Copilot Studio, this time we’ll explore “Self-RAG,” one of the Advanced RAG techniques.
Self-RAG
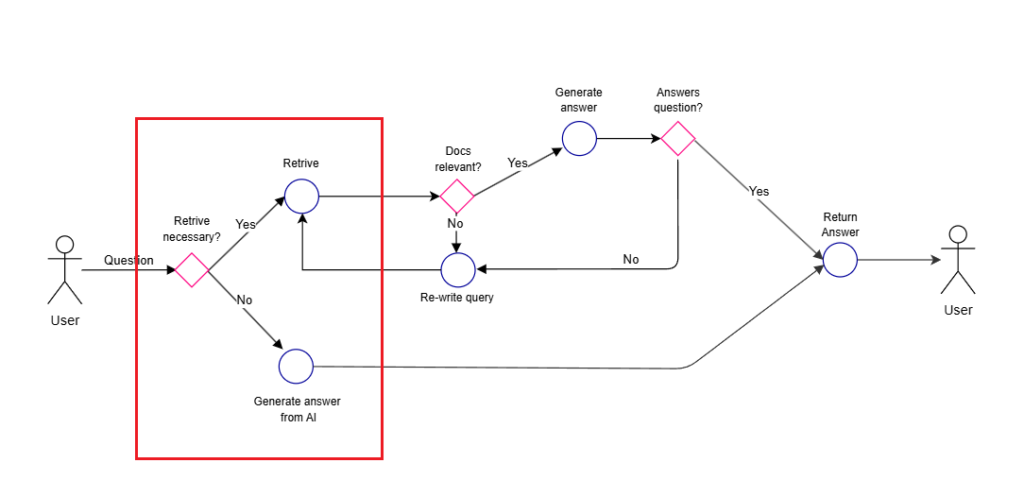
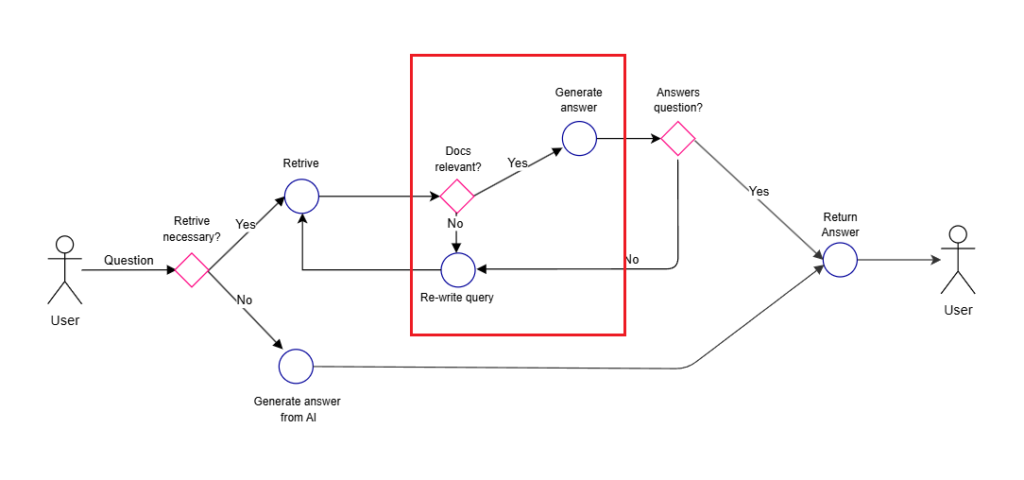
Self-RAG is a methodology developed around October 2023, designed to improve response quality and reduce hallucinations.
- Determine whether information retrieval is necessary (if not, generate response directly)
- If retrieval is needed, fetch multiple documents and evaluate their relevance to the question
- Generate responses based on relevant documents
- Evaluate each response and synthesize the final answer
Ideally, Self-RAG involves fine-tuning LLMs to create separate “critic” and “generator” models. However, since that level of customization isn’t feasible in our context, we’ll utilize GPT4o for all these functions.
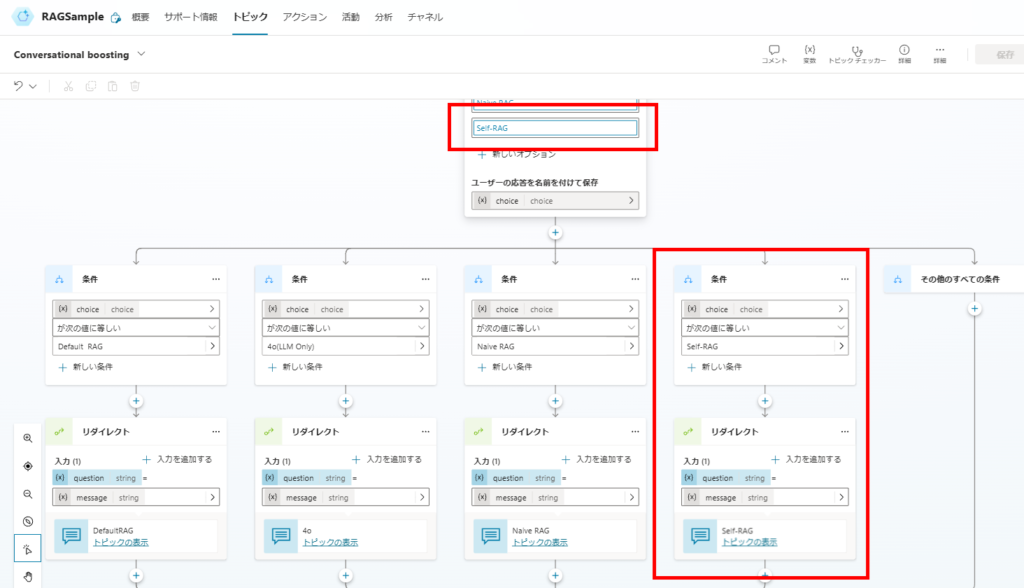
Implementing Self-RAG in Copilot Studio

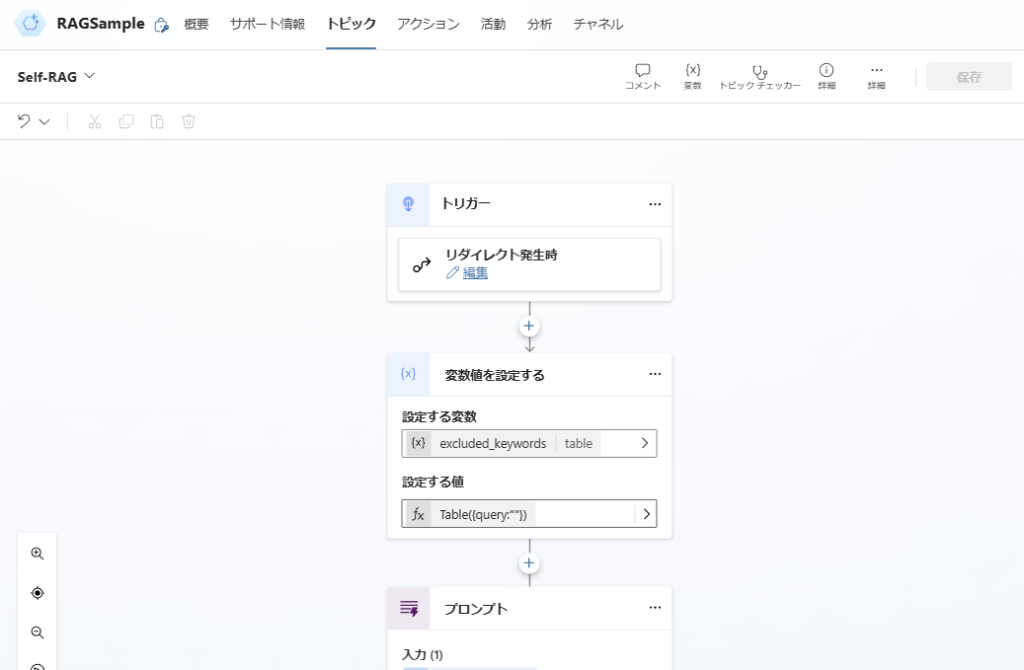
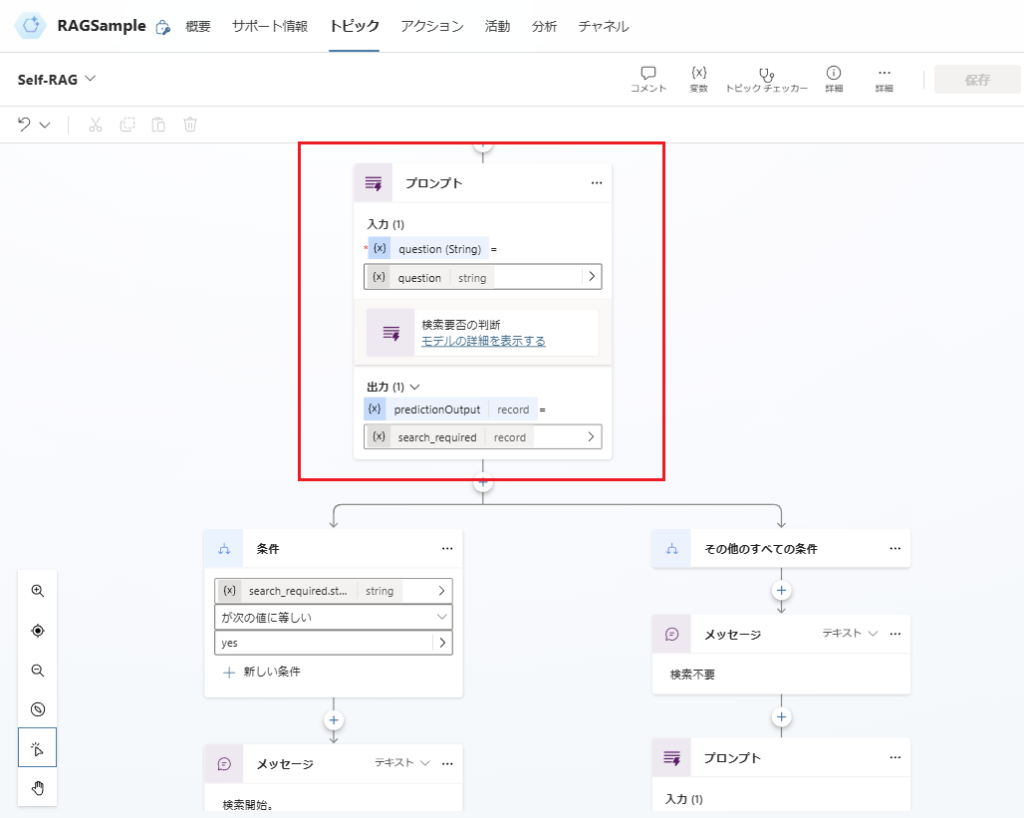
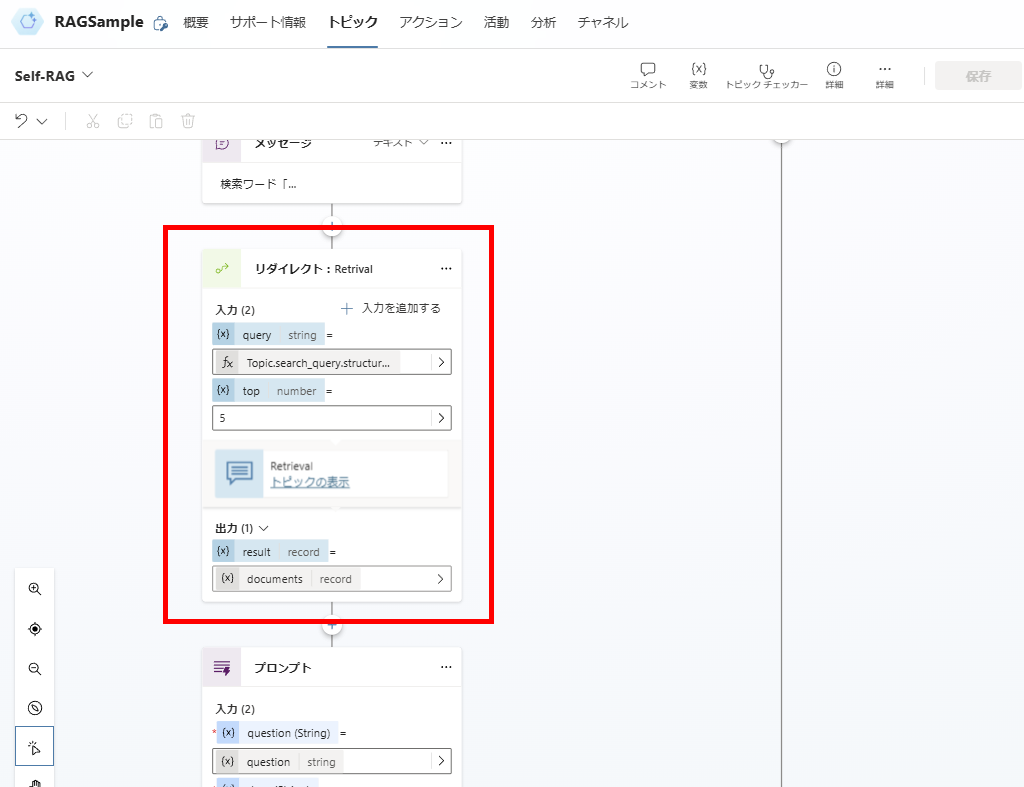
Implementation
Since our main focus is on building Self-RAG in Copilot Studio, we’ll prioritize the implementation over optimizing accuracy (such as prompt engineering).
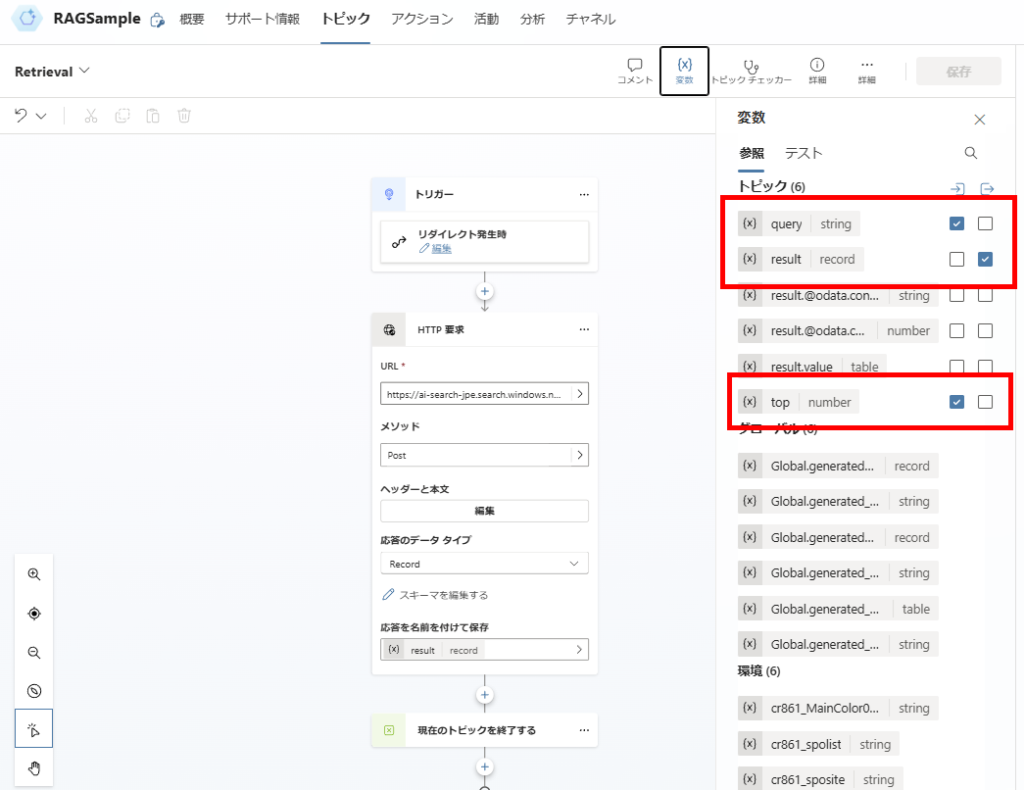
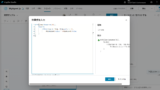
Trigger and Variable Declaration
Determining Search Necessity
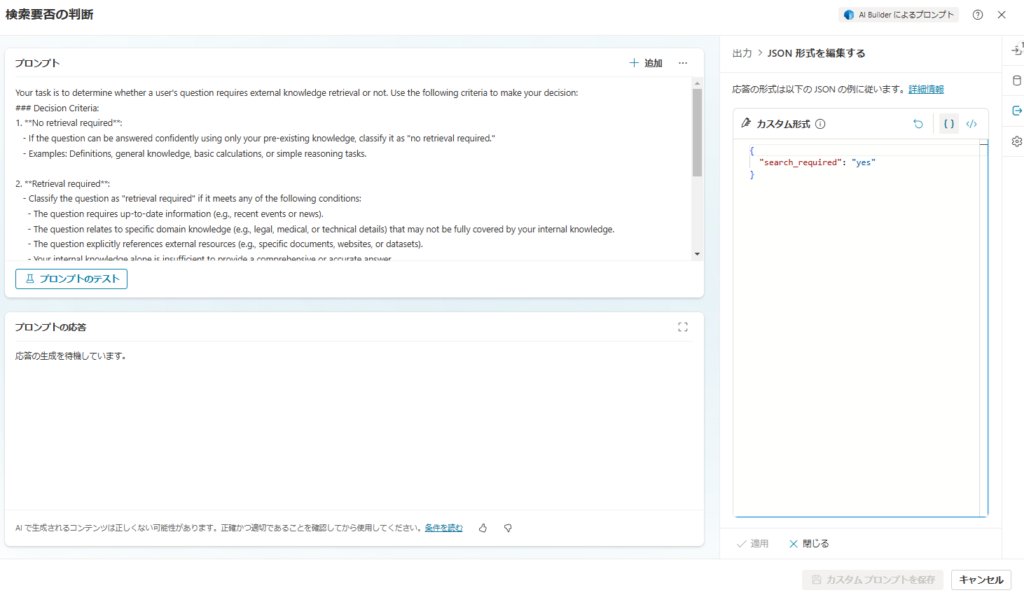
Your task is to determine whether a user's question requires external knowledge retrieval or not. Use the following criteria to make your decision:
### Decision Criteria:
1. **No retrieval required**:
- If the question can be answered confidently using only your pre-existing knowledge, classify it as "no retrieval required."
- Examples: Definitions, general knowledge, basic calculations, or simple reasoning tasks.
2. **Retrieval required**:
- Classify the question as "retrieval required" if it meets any of the following conditions:
- The question requires up-to-date information (e.g., recent events or news).
- The question relates to specific domain knowledge (e.g., legal, medical, or technical details) that may not be fully covered by your internal knowledge.
- The question explicitly references external resources (e.g., specific documents, websites, or datasets).
- Your internal knowledge alone is insufficient to provide a comprehensive or accurate answer.
### Output Format:
Provide your answer in the following format:
- **"search_required": "yes"** (if retrieval is needed)
- **"search_required": "no"** (if retrieval is not needed)
Here is the user's question:
Question: {question}
Respond with the required output format only, without any additional explanation or context.
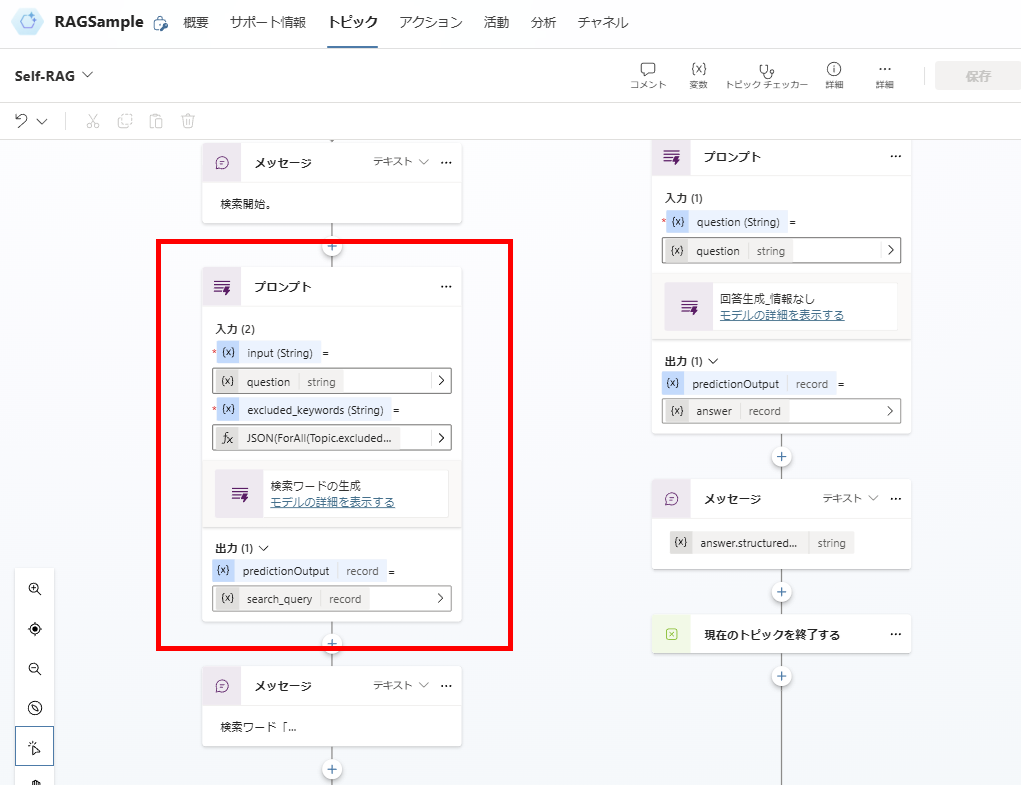
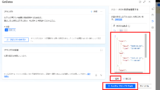
Relevance Evaluation
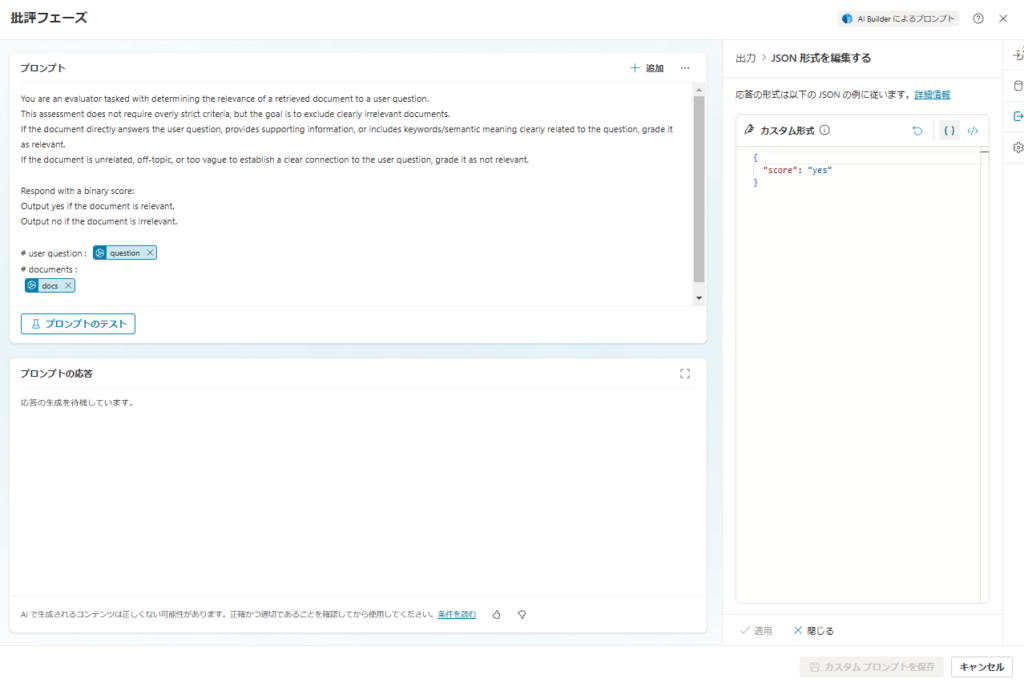
You are an evaluator tasked with determining the relevance of a retrieved document to a user question.
This assessment does not require overly strict criteria, but the goal is to exclude clearly irrelevant documents.
If the document directly answers the user question, provides supporting information, or includes keywords/semantic meaning clearly related to the question, grade it as relevant.
If the document is unrelated, off-topic, or too vague to establish a clear connection to the user question, grade it as not relevant.
Respond with a binary score:
Output yes if the document is relevant.
Output no if the document is irrelevant.
# user question : {question}
# documents :
{docs}
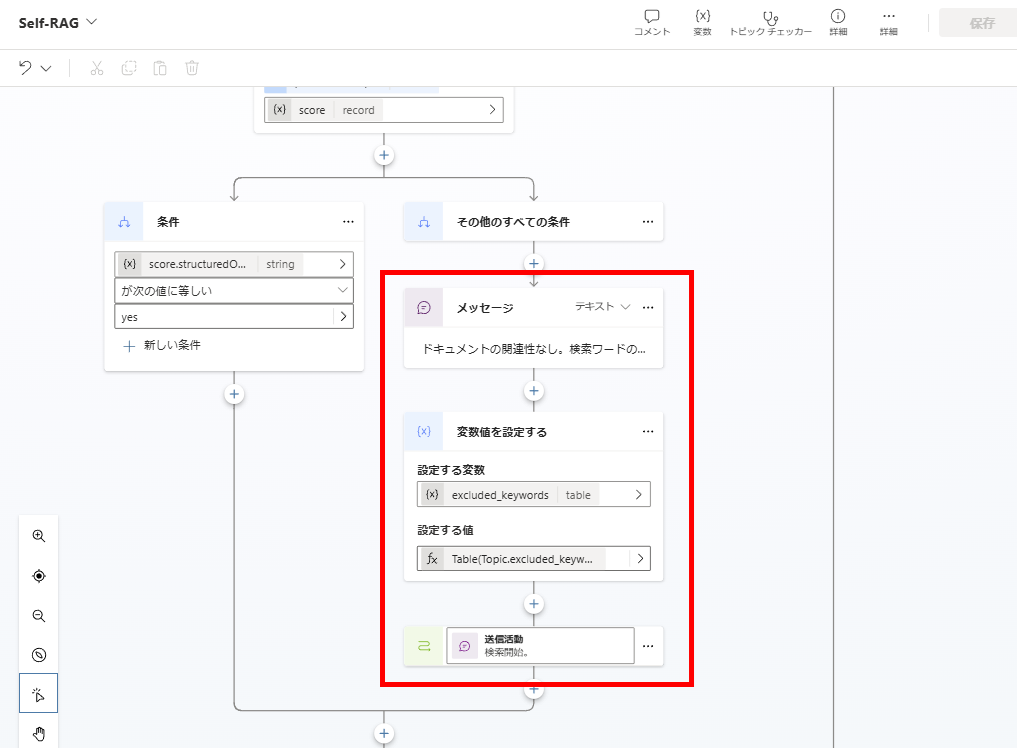
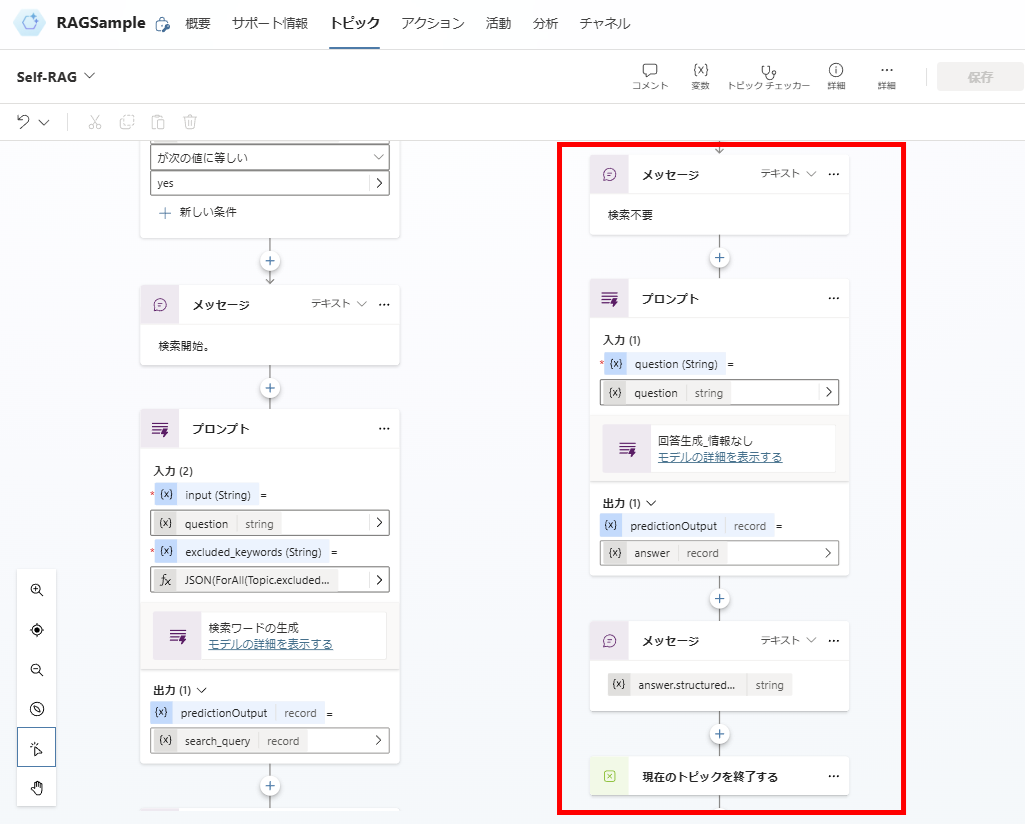
If relevance is confirmed, proceed to response generation.
Response Generation and Answer Validation
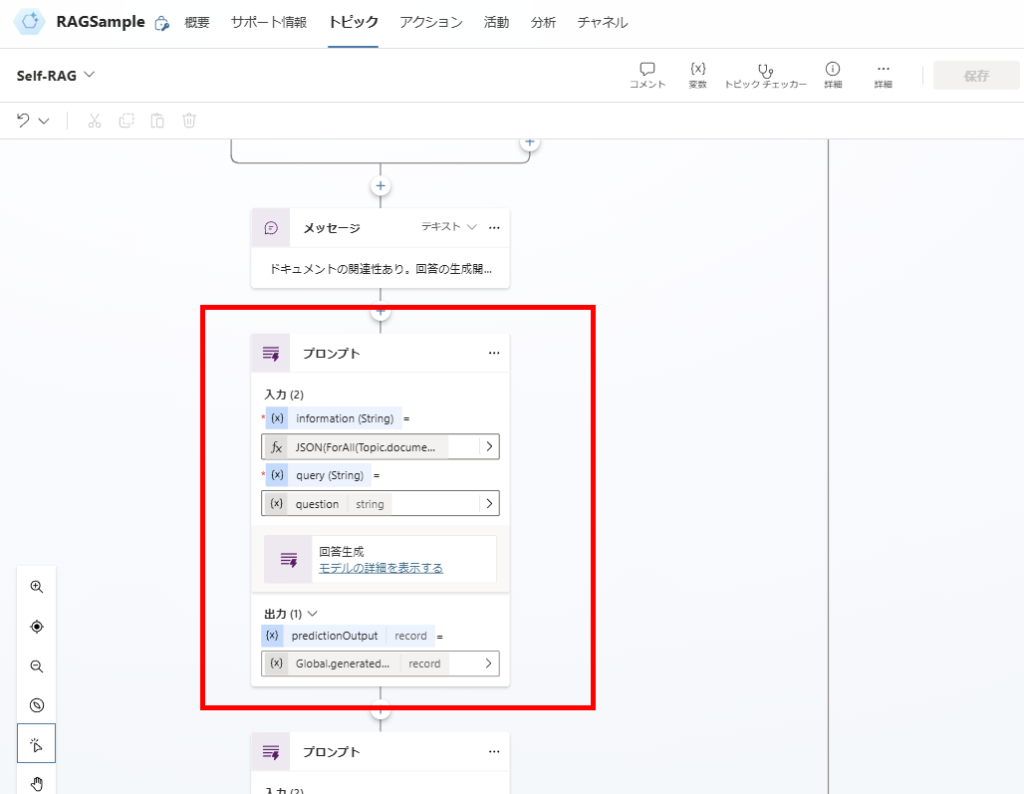
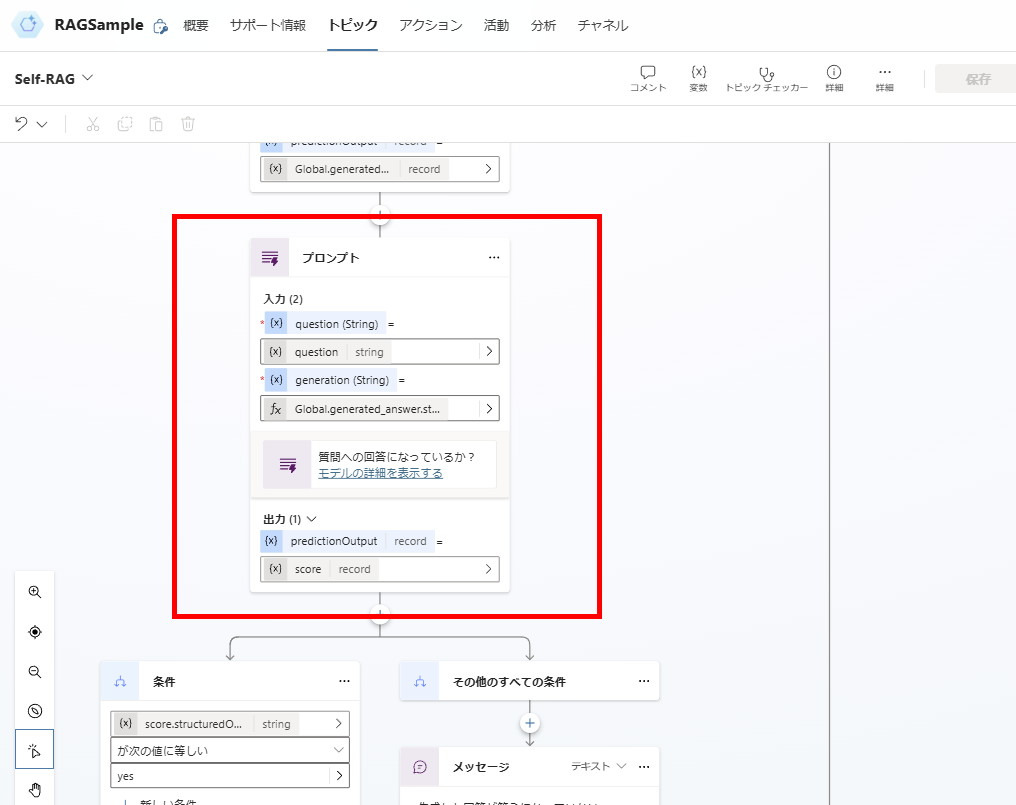
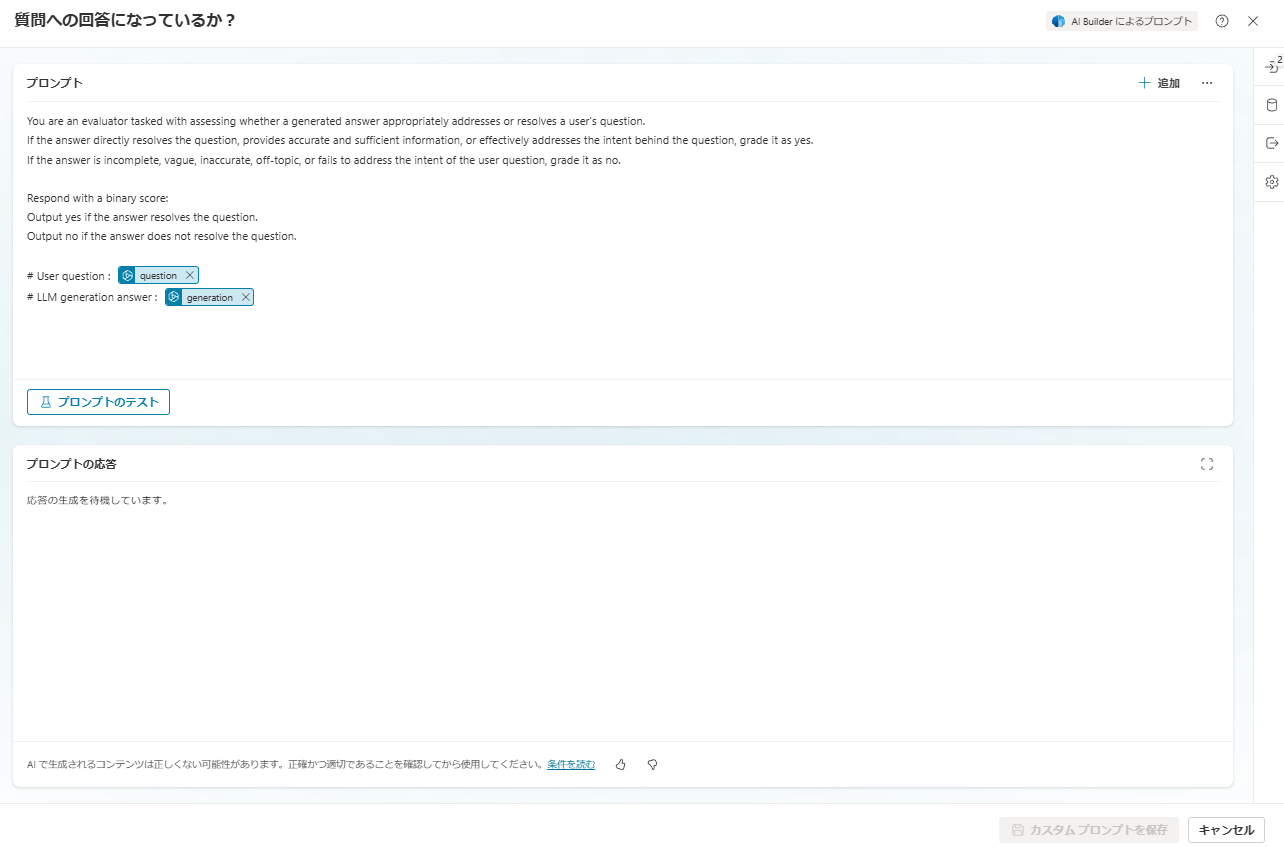
You are an evaluator tasked with assessing whether a generated answer appropriately addresses or resolves a user's question.
If the answer directly resolves the question, provides accurate and sufficient information, or effectively addresses the intent behind the question, grade it as yes.
If the answer is incomplete, vague, inaccurate, off-topic, or fails to address the intent of the user question, grade it as no.
Respond with a binary score:
Output yes if the answer resolves the question.
Output no if the answer does not resolve the question.
# User question : {question}
# LLM generation answer : {generation}
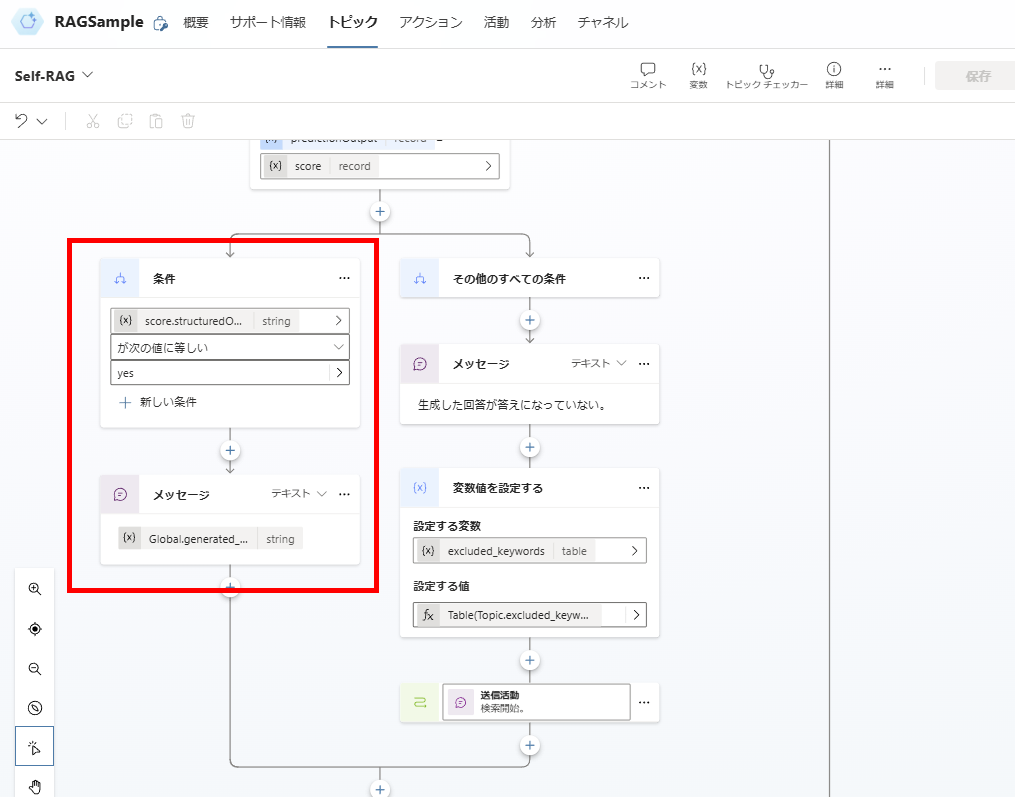
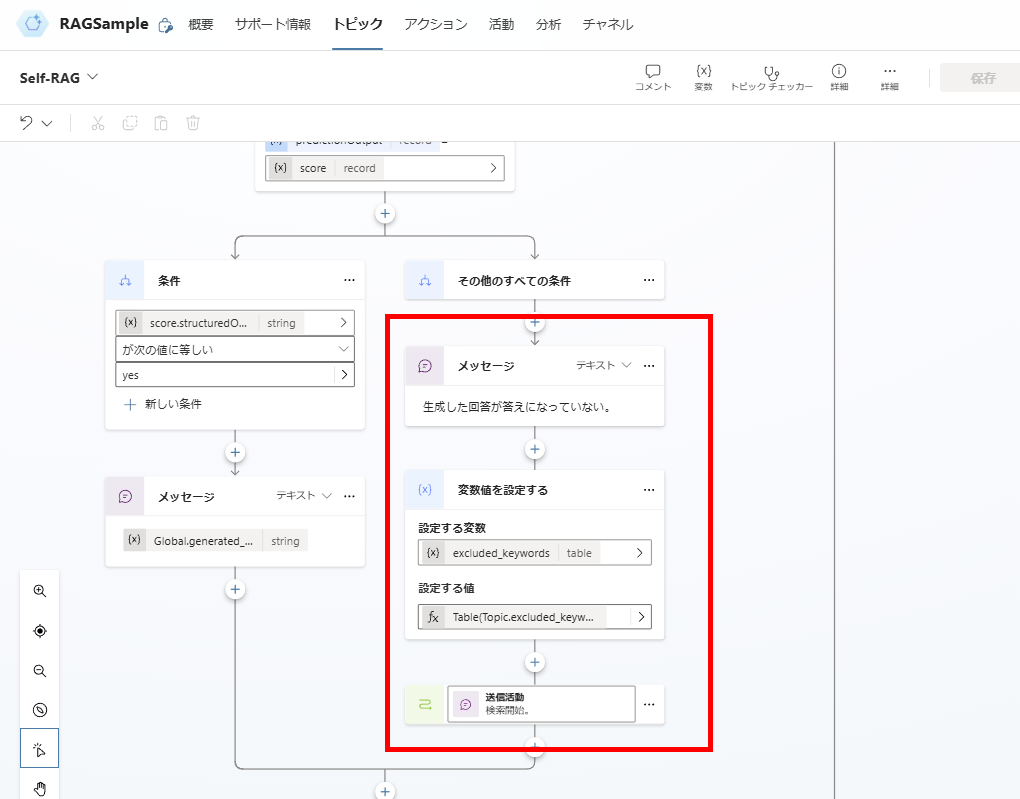
This completes the topic implementation.
Optional: Integration with Conversational Boosting
Testing Results
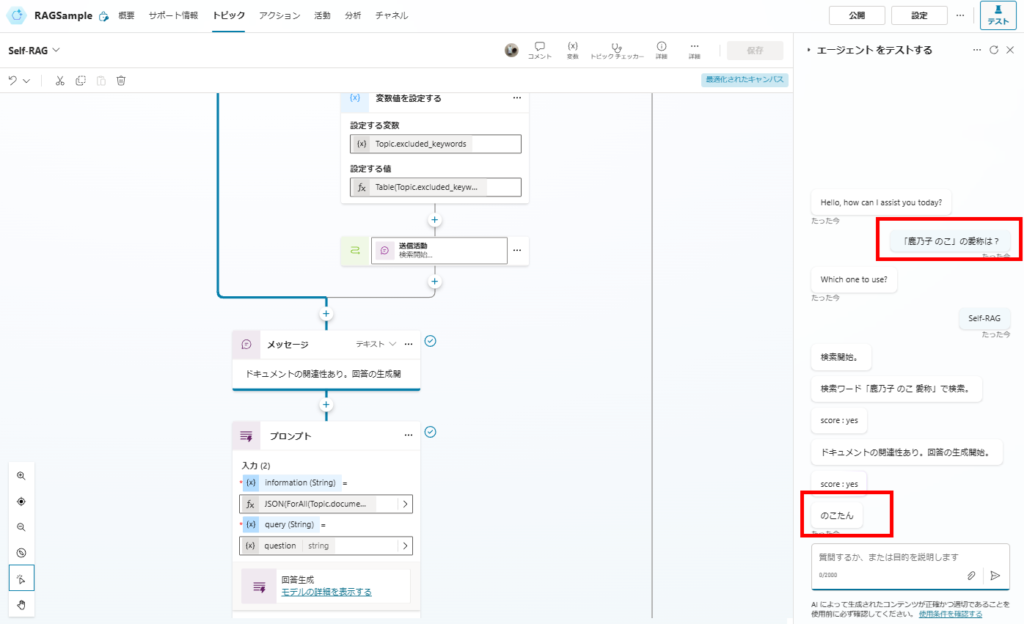
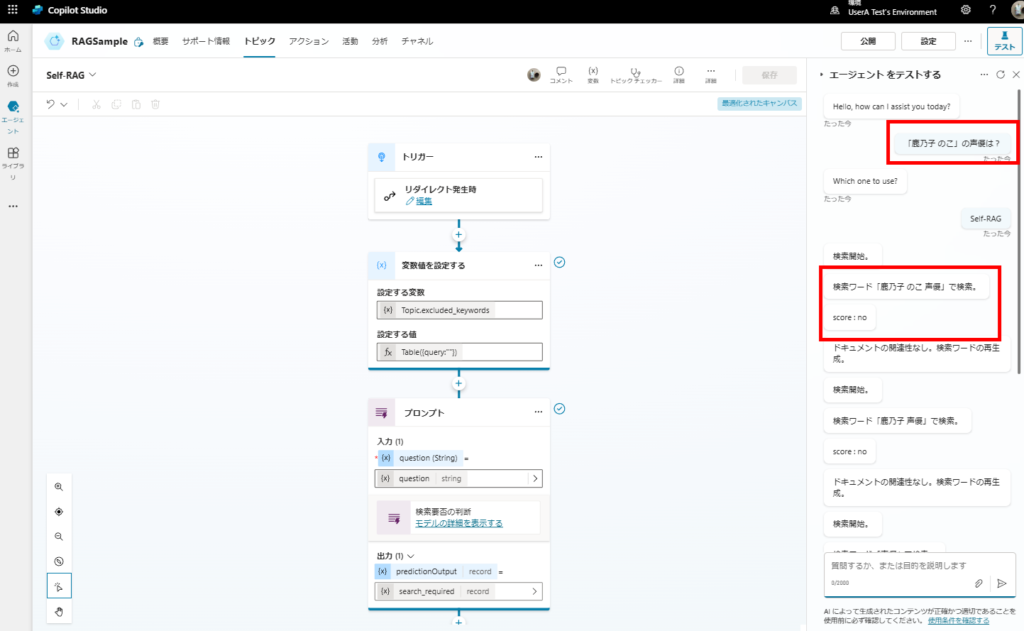
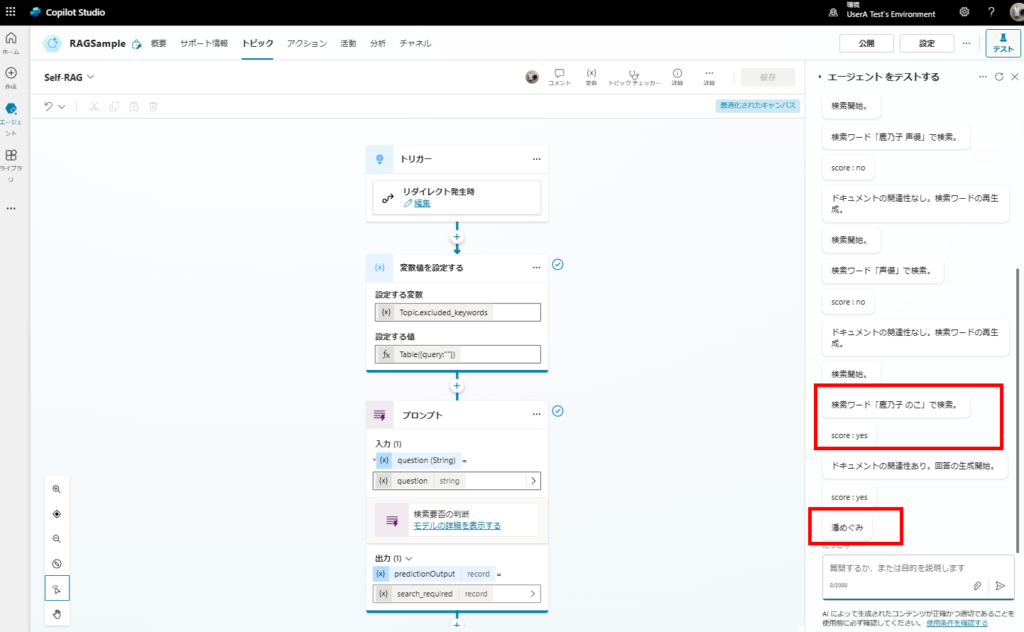
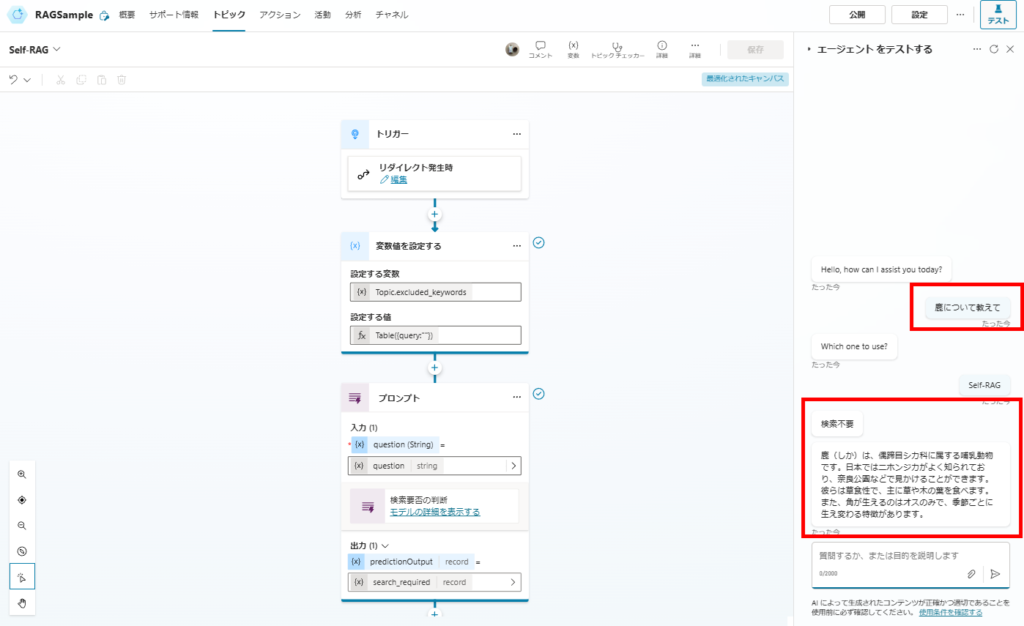
These results confirm the improved accuracy of our implementation. In the next article, I’d like to experiment with CRAG and other advanced techniques.
コメント