Azure AI Searchの検索対象にSharePointを追加する手順をメモ。
AI Searchの検索対象にSharePoint Onlineを追加
プレビューだけど、AI Searchは検索対象にSharePointのドキュメントライブラリを設定することが可能。
※今のところ細々制限があるので注意。
- 拡張子制限あり
- リストは対象外
- ASPXも対象外 など
今回はAI Searchの検索対象にSharePointを追加するのが意外と大変だったので、その手順をめも。
手順
大まかな手順は以下の通り。
- 検索対象のSharePointサイトの作成
- AI Searchリソースの作成
- Entra IDにアプリを登録
- データソース、インデックス、インデクサの作成
以下詳細。
手順0 : SharePointサイトの作成
まずは検索対象とするSharePointサイトを作成。
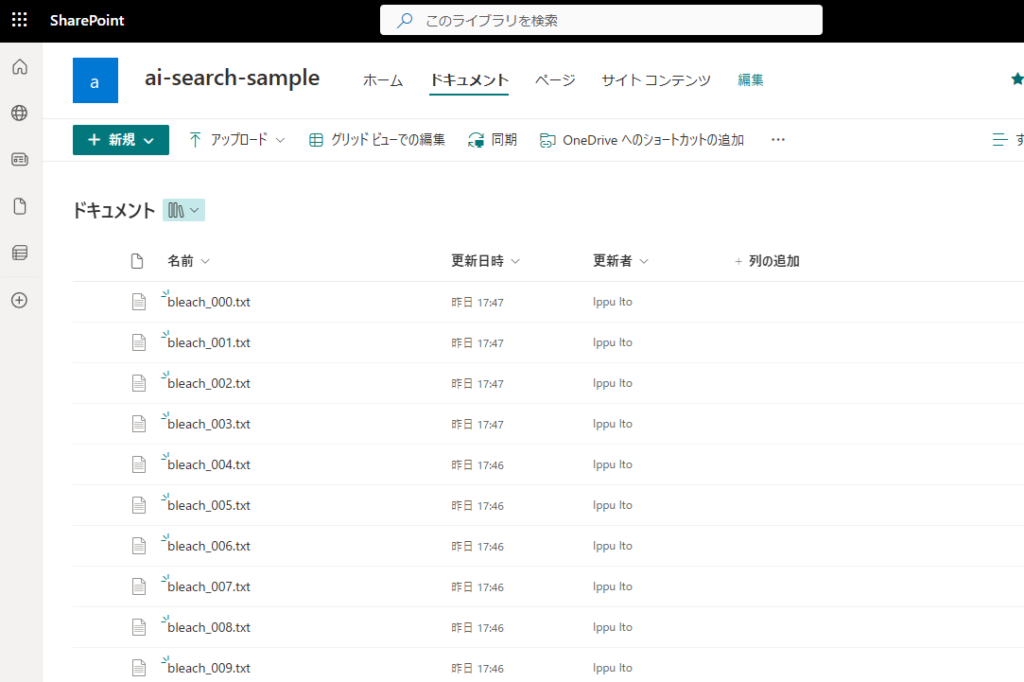
ドキュメントライブラリには、以下のPythonで取得→チャンク化したWikipediaの情報(BLEACH, NARUTO, ONEPIECE)を保存。
![]()
Python WikipediaのURLから記事内容を抽出しチャンク分割&テキスト保存する
RAGを試すためのデータが欲しかったので、WikipediaのURLを指定し、コンテンツをチャンク化してtxtに保存するコードを作成。必要なライブラリ以下、必要なライブラリ。pip install langchain langchain_c...
ippu-biz.com
2025.02.08
手順1 : AI Searchリソースの作成
Azureポータルを開き、AI Searchの[作成]を選択、
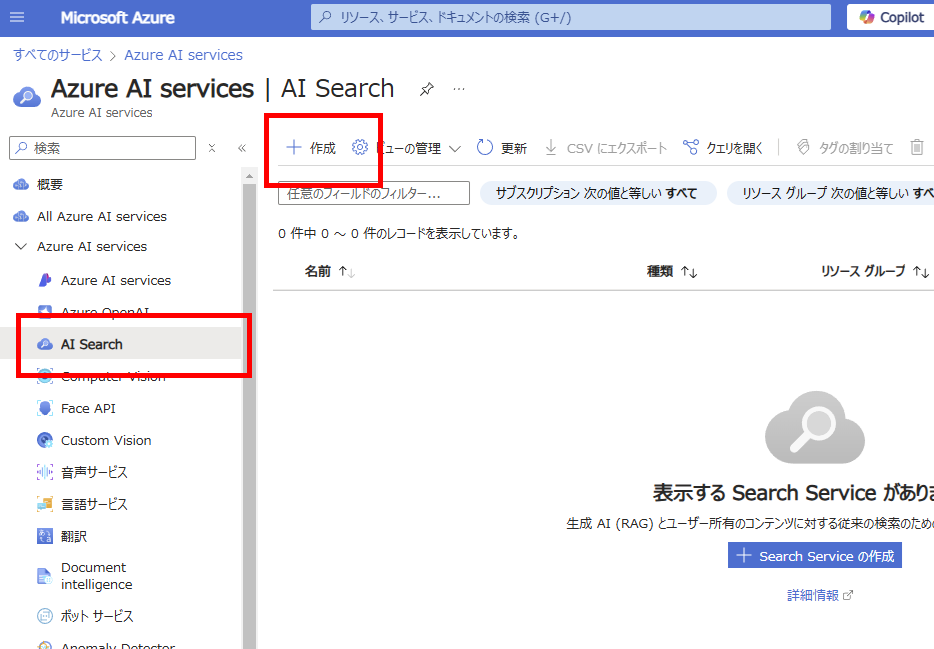
サービス名やリージョンを選択し、リソースを作成する。※今回は実運用しないのでFree。
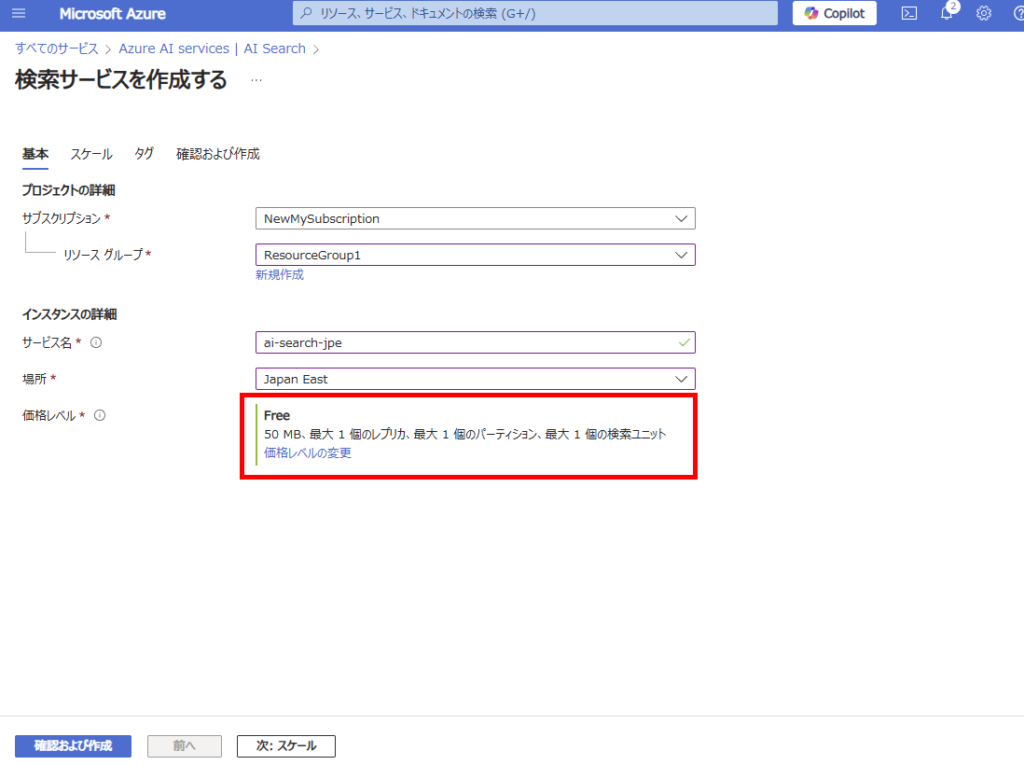
それ以外はすべて既定で。
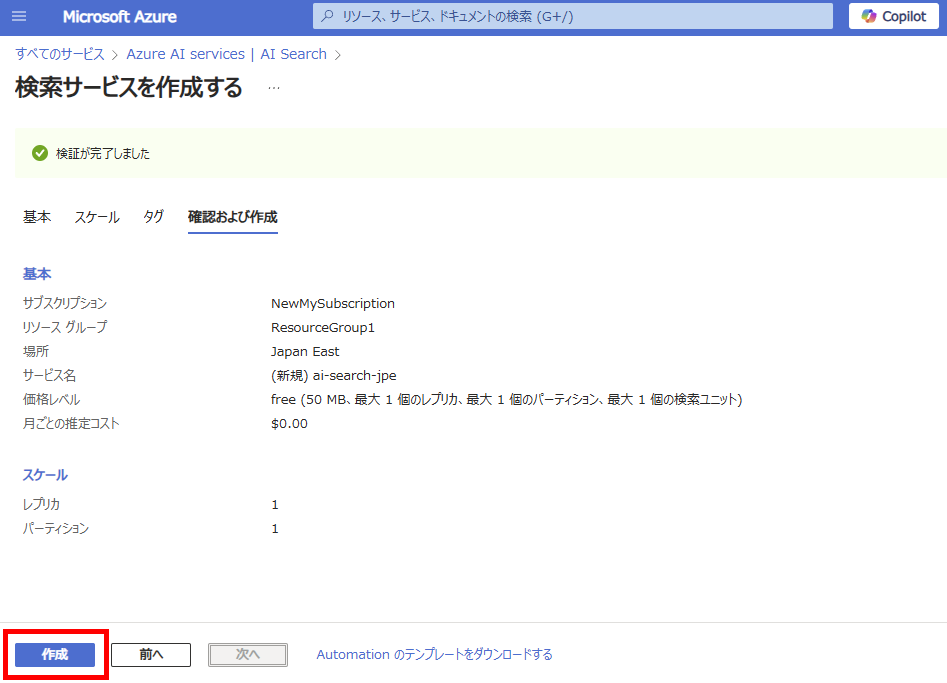
リソースの作成が完了したら、AI Searchの[ID]タブより、[システム割り当てID]をオンにする。
※オブジェクトIDはメモる必要なし
※オブジェクトIDはメモる必要なし
Entra IDにアプリを登録
続いてEntra IDを選択して、
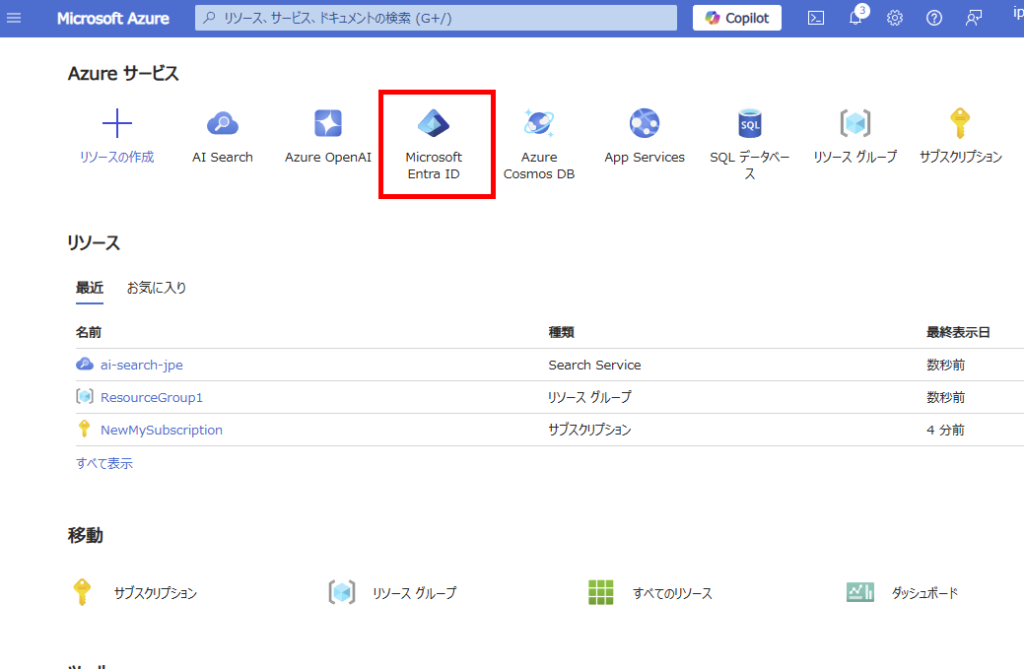
[アプリの登録]から[新規登録]を選ぶ。
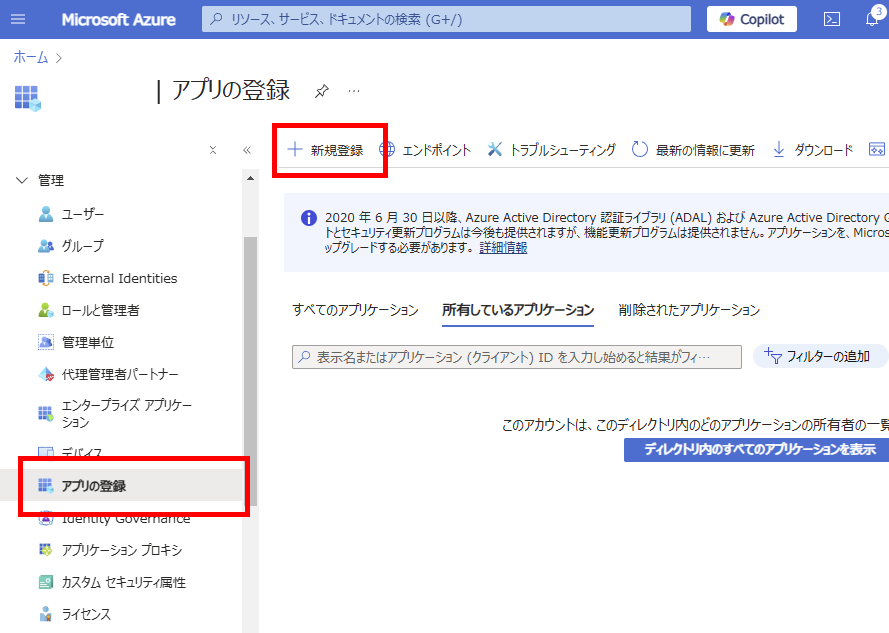
今回は同一テナントのSPOサイトを検索対象にするので、「この組織の~~」を選択し、登録。
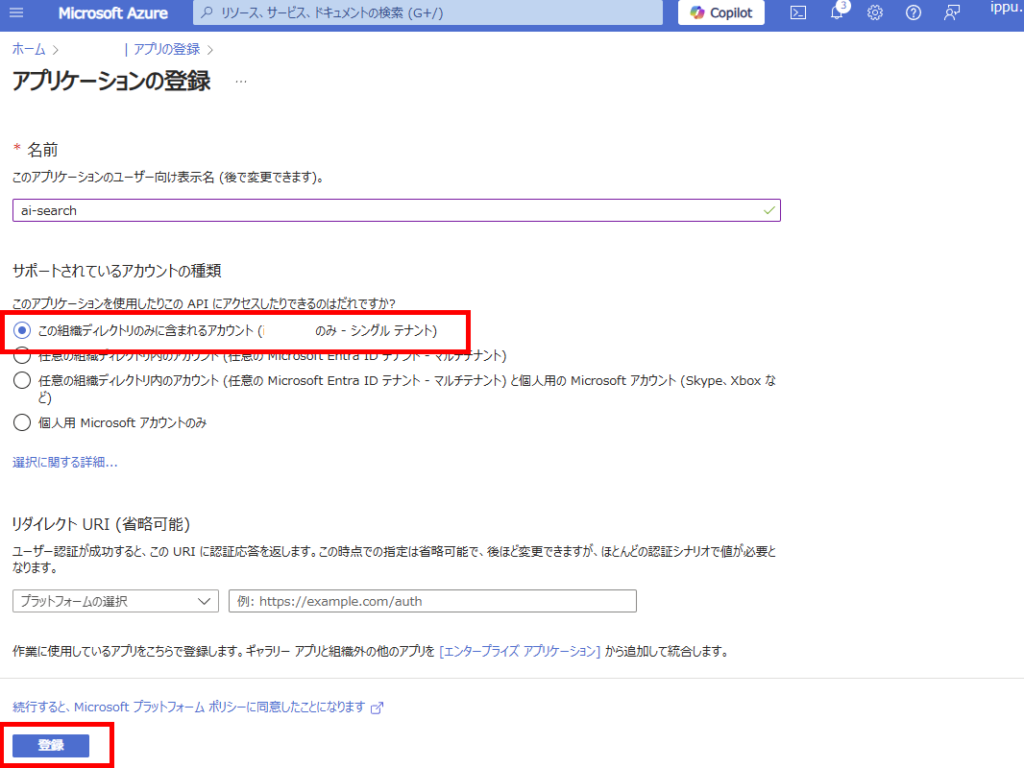
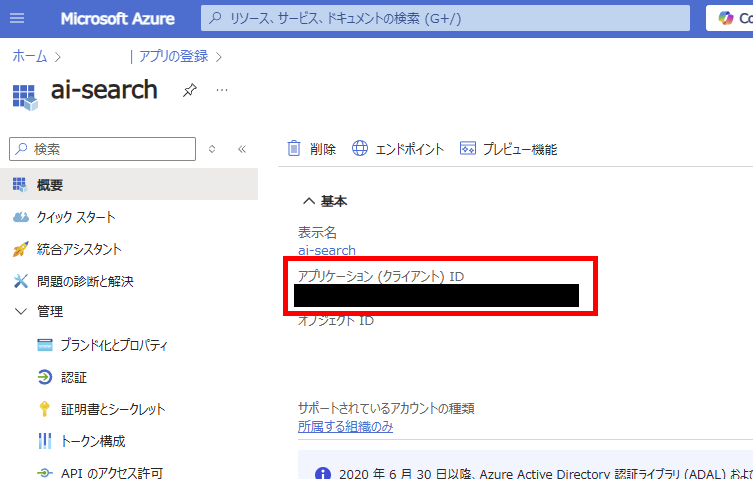
アプリ登録が完了したら、[概要]タブの[アプリケーションID]をメモする(メモ1)。
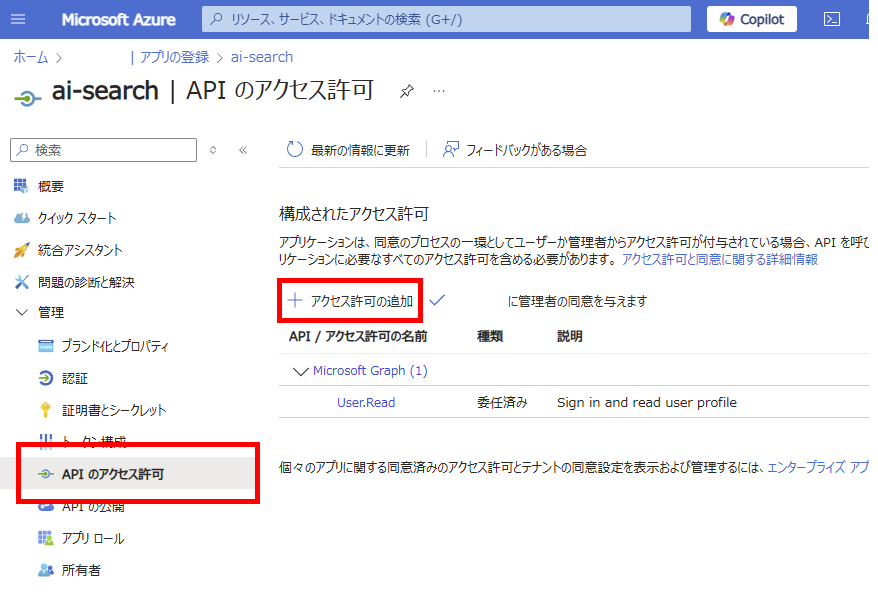
登録したアプリの[APIのアクセス許可]から[アクセス許可の追加]を選んで、
[Microsoft Graph]を選択。
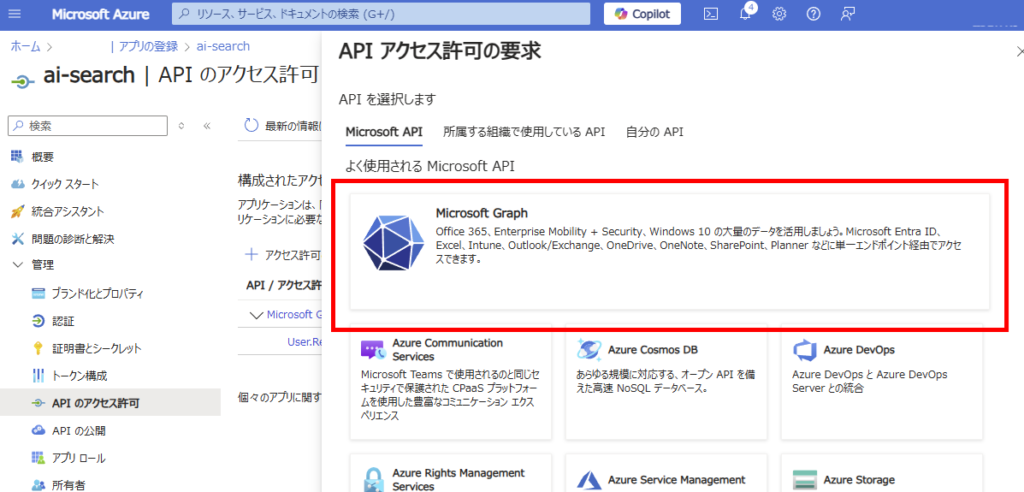
[アプリケーションの許可]から「Sites.Read.All」と
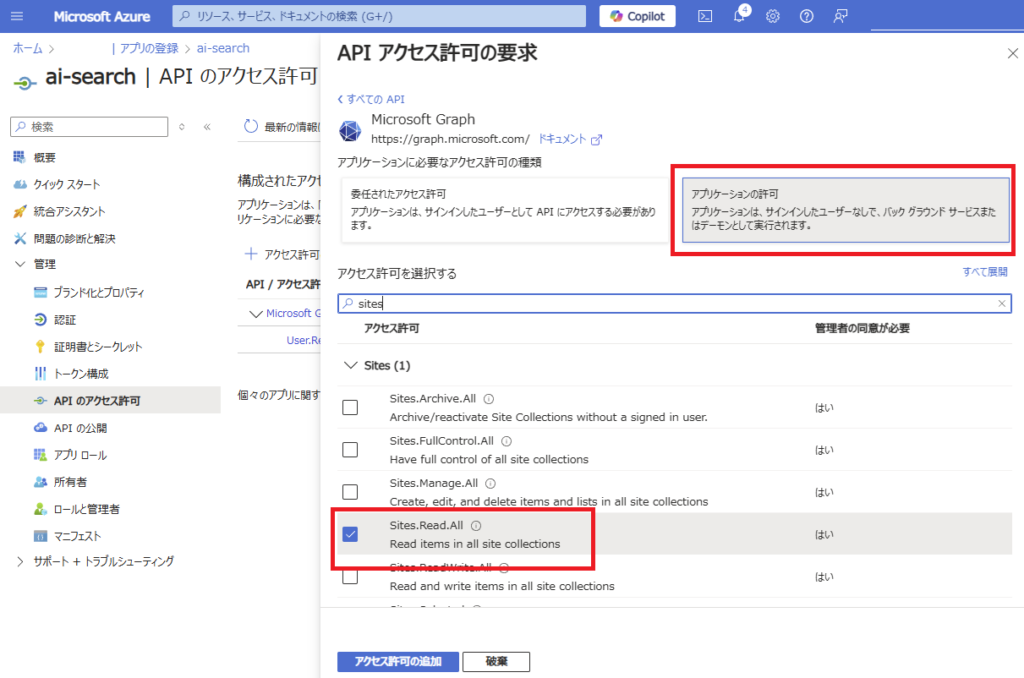
「Files.Read.All」を選び、[アクセス許可の追加]を押す。
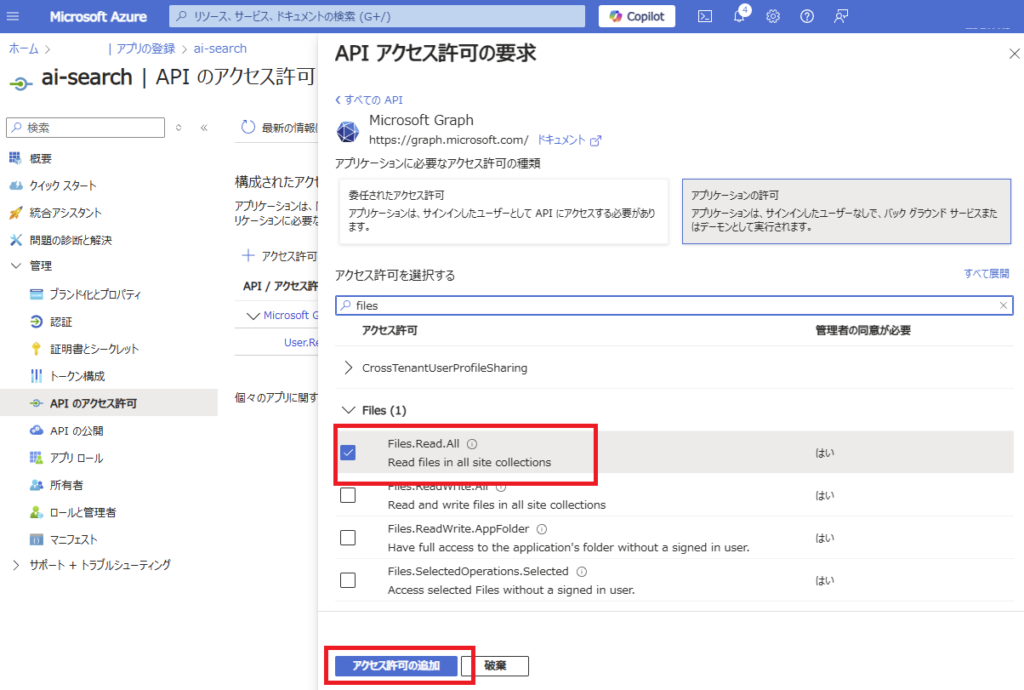
[管理者の同意]を与える。
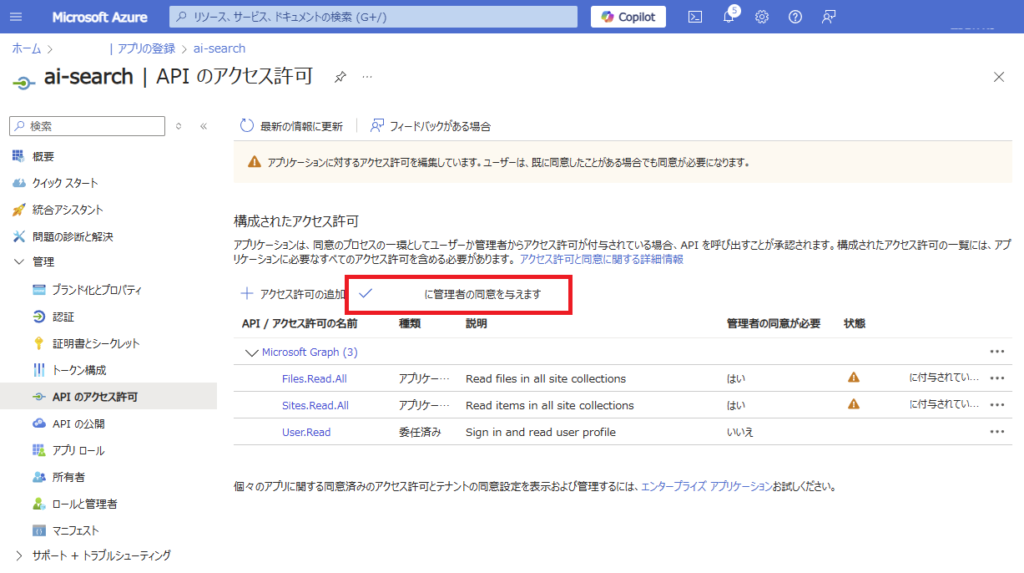
続いて[認証]から、[次のモバイルとデスクトップのフローを有効にする]を「はい」にして一度保存し、
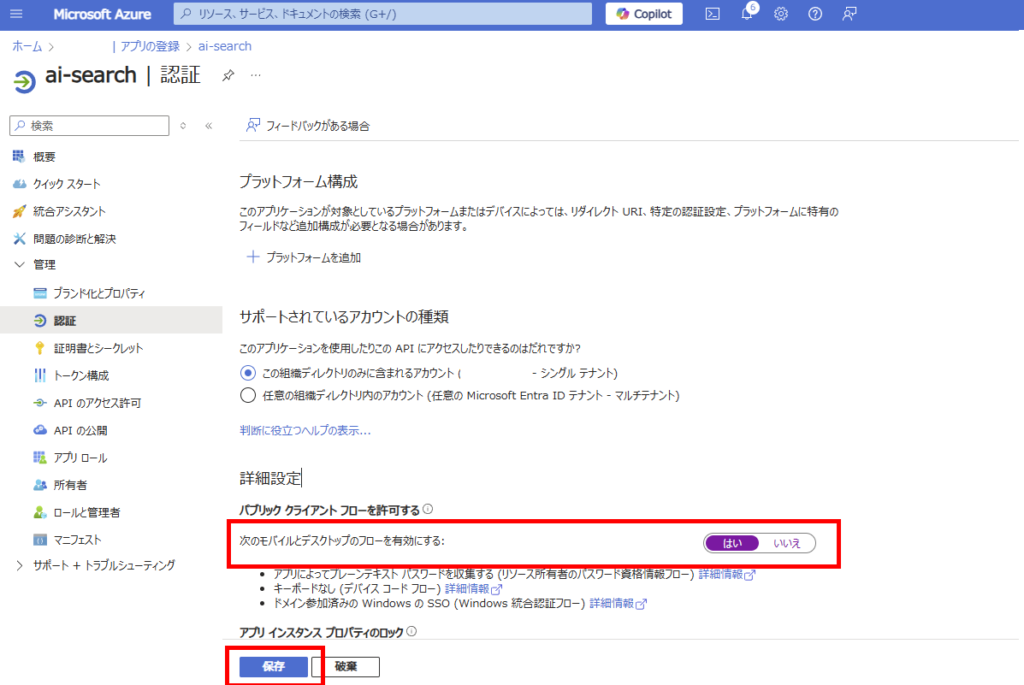
[プラットフォームを追加]から、[モバイルアプリケーションとデスクトップアプリケーション]を追加、
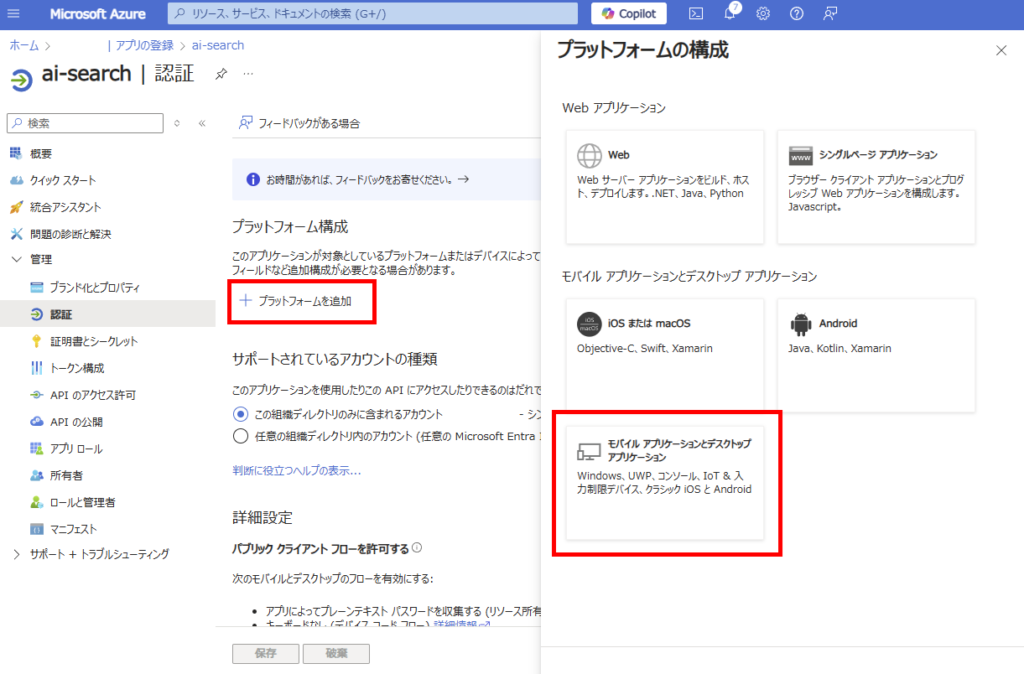
「https://login.micosoftonline~~~」を選び、構成。
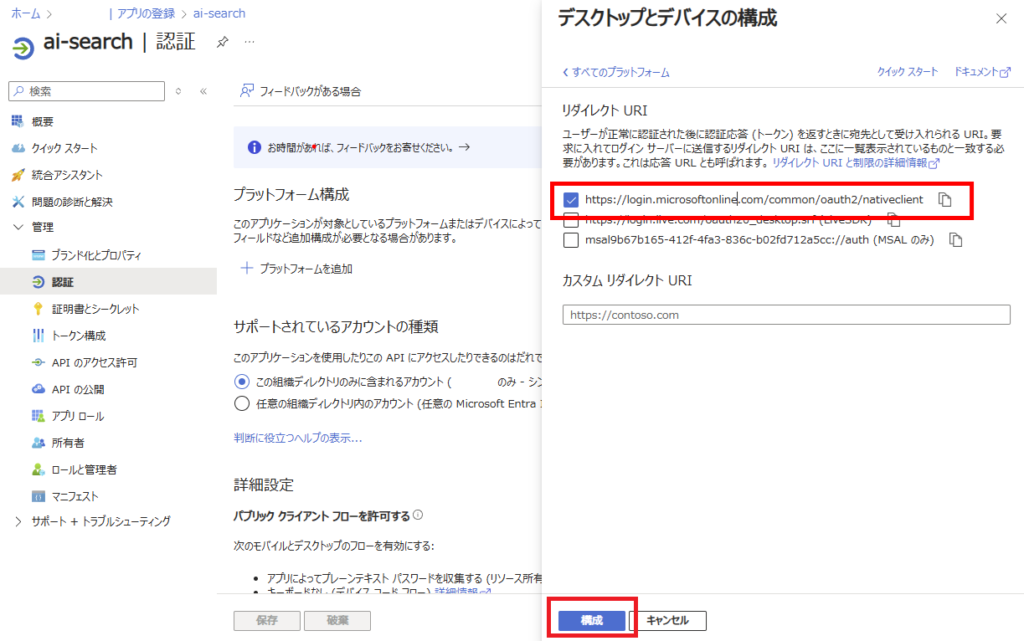
最後に[証明書とシークレット]タブから、[新しいクライアントシークレット]を追加して、任意の有効期限で追加。
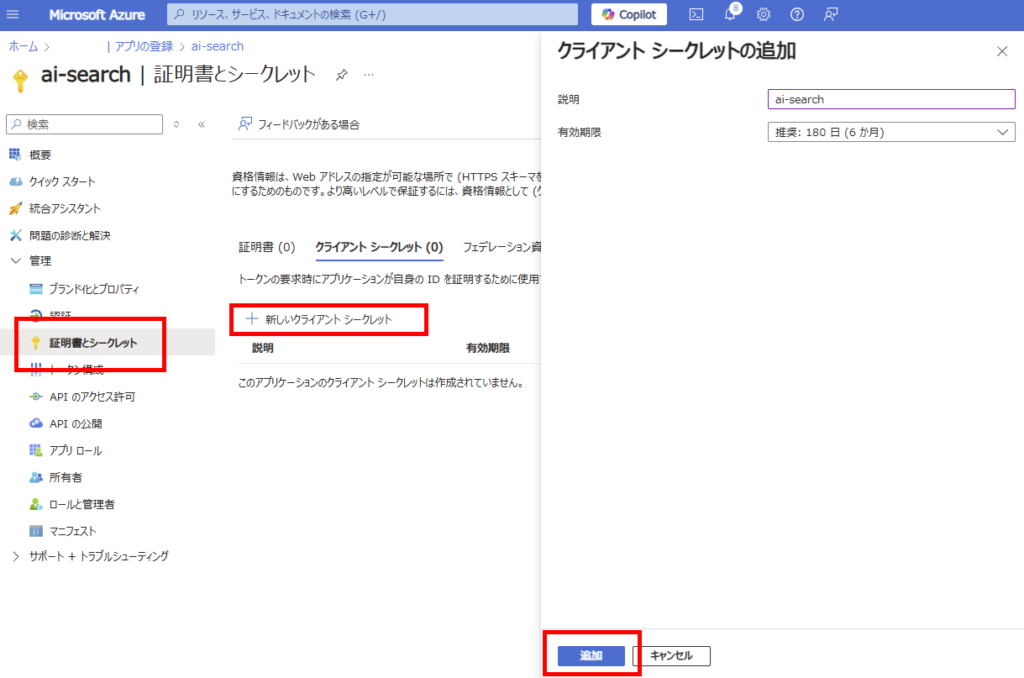
作成されたクライアントシークレットをメモする(メモ2)。
以上でEntra IDの登録は完了。
AI Search : データソースの追加
続いてAI Searchに戻り、[データソース]タブから[データソースの追加(JSON)]を選択し、
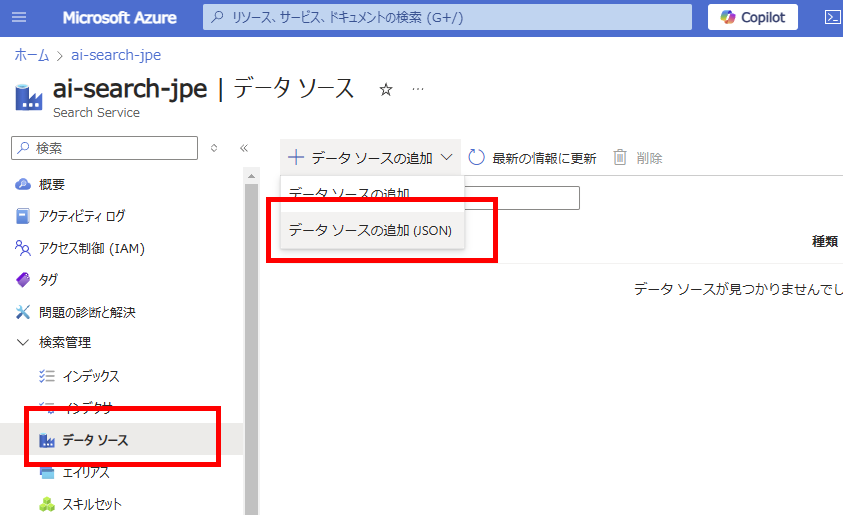
以下のJSONを設定。
{
"name": "【任意のデータソース名(サンプルはsharepoint-datasource)】",
"type": "sharepoint",
"credentials": {
"connectionString": "SharePointOnlineEndpoint=【SPOサイトURL(~~/sites/サイト名まで)】;ApplicationId=【アプリID(メモ1)】;ApplicationSecret=【シークレット(メモ2)】;"
},
"container": {
"name": "【対象のドキュメントライブラリ(詳しくは後述)】"
}
}
■type:SharePointの場合は「sharepoint」を指定
■container/name
■container/name
- defaultSiteLibrary:サイトの既定のドキュメント ライブラリにあるすべてのコンテンツのインデックスを作成
- allSiteLibraries:サイト内のすべてのドキュメント ライブラリにあるすべてのコンテンツのインデックスを作成
- useQuery:”query” で定義されているコンテンツのインデックスのみを作成
※クエリについてはこちら
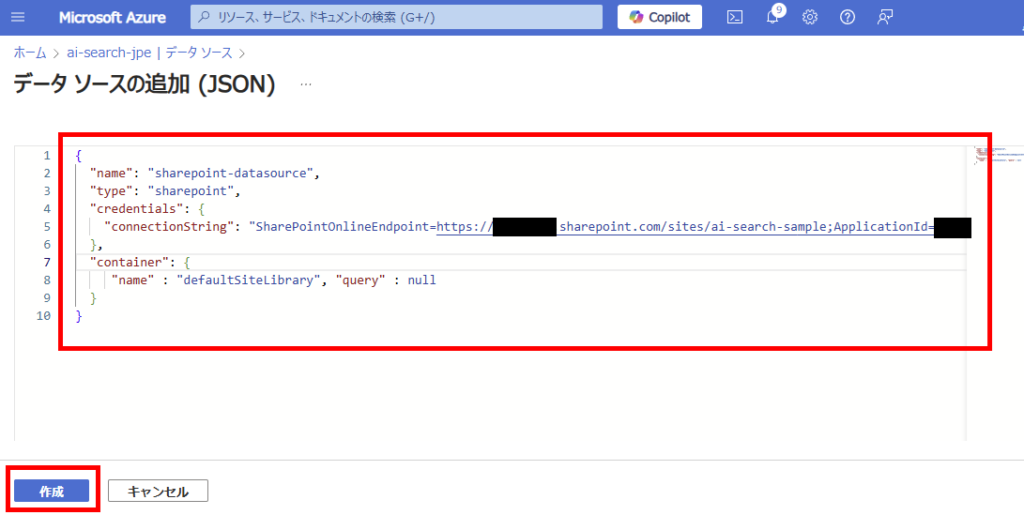
インデックスの作成
続いてインデックス(検索に使用する列や属性など)を定義。[インデックス]から[インデックスの追加(JSON)]を選び、任意の列などを指定する。
今回は動作確認なので、最低限(ベクトル検索は埋め込みにお金かかるのでひとまず使用しない)。
今回は動作確認なので、最低限(ベクトル検索は埋め込みにお金かかるのでひとまず使用しない)。
{
"name" : "sharepoint-index",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "metadata_spo_item_name", "type": "Edm.String", "key": false, "searchable": true, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_path", "type": "Edm.String", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_content_type", "type": "Edm.String", "key": false, "searchable": false, "filterable": true, "sortable": false, "facetable": true },
{ "name": "metadata_spo_item_last_modified", "type": "Edm.DateTimeOffset", "key": false, "searchable": false, "filterable": false, "sortable": true, "facetable": false },
{ "name": "metadata_spo_item_size", "type": "Edm.Int64", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": false }
]
}
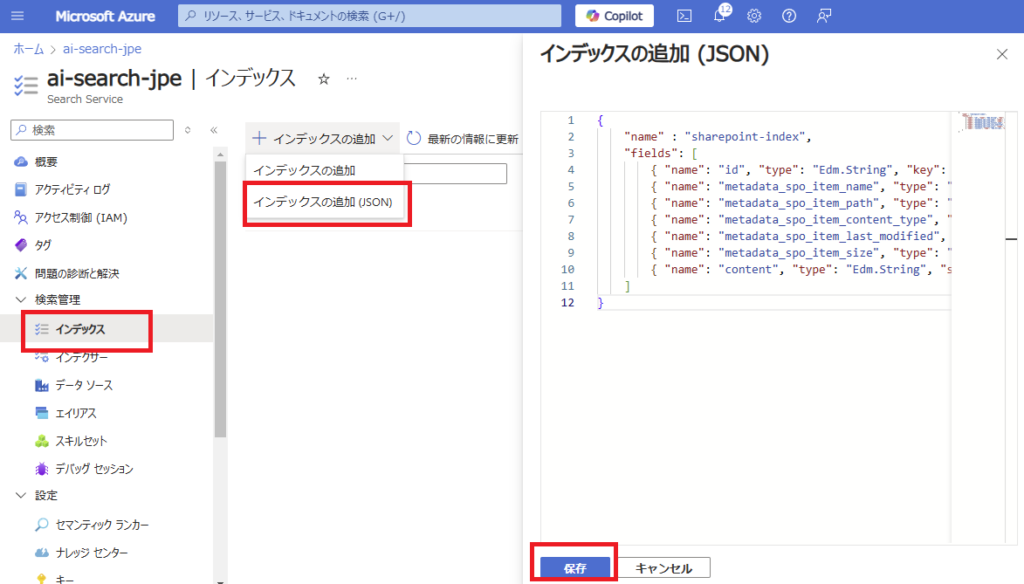
インデクサーの作成
最後にインデクサーを作成する。[インデクサー]から[インデクサー(JSONの追加)]を選び、以下を設定して保存。
※今回はサンプルなのでスキルセットはなし(チャンク化はPython側で実施済み)。
※今回はサンプルなのでスキルセットはなし(チャンク化はPython側で実施済み)。
{
"name" : "sharepoint-indexer",
"dataSourceName" : "sharepoint-datasource",
"targetIndexName" : "sharepoint-index",
"parameters": {
"batchSize": null,
"maxFailedItems": null,
"maxFailedItemsPerBatch": null,
"base64EncodeKeys": null,
"configuration": {
"indexedFileNameExtensions" : ".txt, .pdf",
"excludedFileNameExtensions" : ".png, .jpg",
"dataToExtract": "contentAndMetadata",
"failOnUnsupportedContentType" : false,
"failOnUnprocessableDocument" : false
}
},
"fieldMappings" : [
{
"sourceFieldName" : "metadata_spo_site_library_item_id",
"targetFieldName" : "id",
"mappingFunction" : {
"name" : "base64Encode"
}
}
]
}
- indexedFileNameExtensions : 検索対象とする拡張子を指定する場合は設定(今回はPDFとtxtのみ)
- excludedFileNameExtensions:検索対象外とする拡張子(今回は画像は対象外)
- failOnUnsupportedContentType:falseにするとサポートされていないドキュメントを検出した際に停止せずスキップする
- failOnUnprocessableDocument:falseにすると識別できないコンテンツがあったときに無視する
インデクサーの作成が成功すると、初回の探索が走り、検索が可能になる。
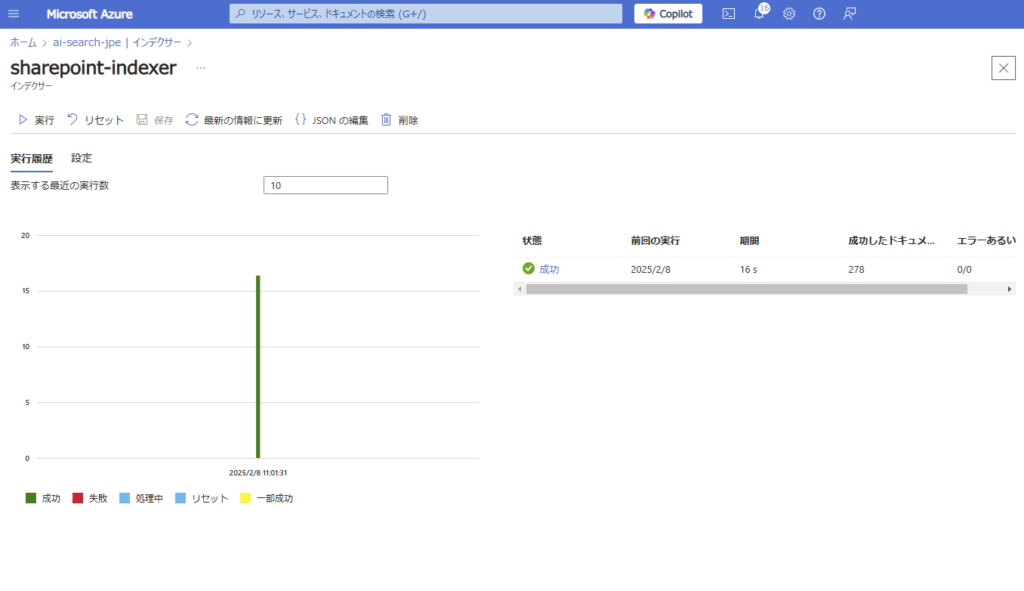
動作確認
動作確認をしてみると、そこそこの精度で情報を検索してくれる。
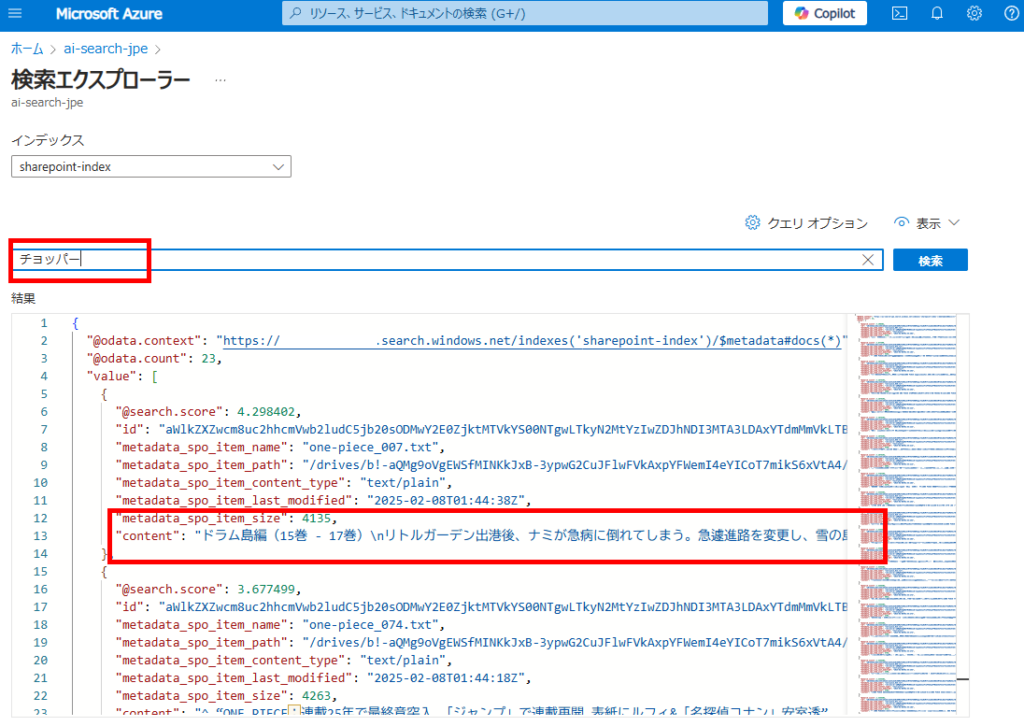
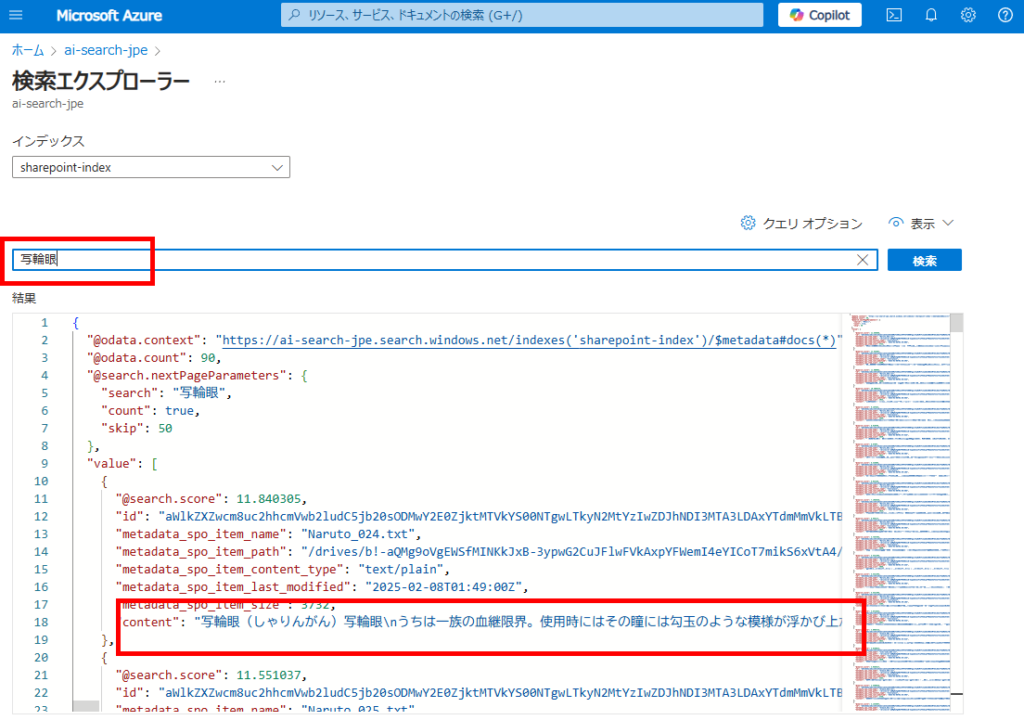
今後この検索を使用し、色々なRAGを試してみる。

コメント