今回はPower Automate経由でOpenAIのWhisper(Speech to Text)を呼び出してみたのでその結果をメモ。
Whisperについて
Whisperは、OpenAIが開発した汎用的な自動音声認識(ASR)モデル。
約68万時間という膨大な多言語・マルチタスクの教師付きデータで学習されており、日本語を含む多言語の音声認識において極めて高い精度を誇る。
Whisper APIの特徴
- 高い堅牢性: アクセント、背景ノイズ、専門用語が含まれる音声でも正確にテキスト化できます。
- 多機能: 単なる文字起こし(Transcriptions)だけでなく、英語への翻訳(Translations)も可能です。
- 対応フォーマット:
mp3,mp4,mpeg,mpga,m4a,wav,webm(最大25MB)
今回の記事では、このWhisper APIをPower AppsおよびPower Automateから直接呼び出し、高精度な「自動文字起こしアプリ」を実装する。
※APIリファレンスはこちら
https://platform.openai.com/docs/api-reference/audio
事前準備:OpenAIのAPIKey取得
まずはOpenAIのトップページに移動して、ログインする。
そしたら右上のアイコンから「View API keys」を選択。
「Create new secret key]を押して、
適当な名前を付けてKeyを作成、
作成されたキーを控えておく。
これで事前準備は完了。
Power Automateの作成
そしたらPower Automateの作成に入っていく。
完成したPower Automateの全体図はこんな感じ。
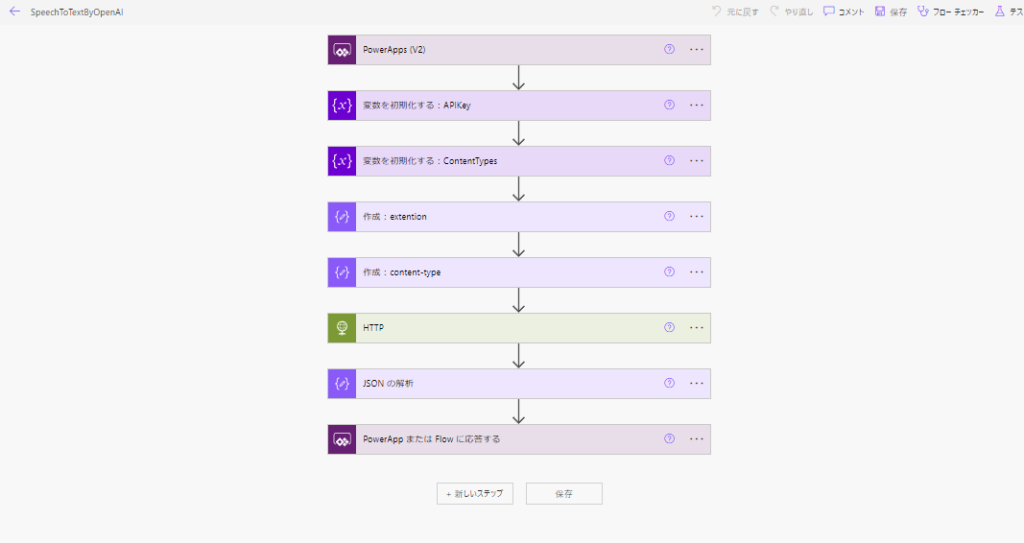
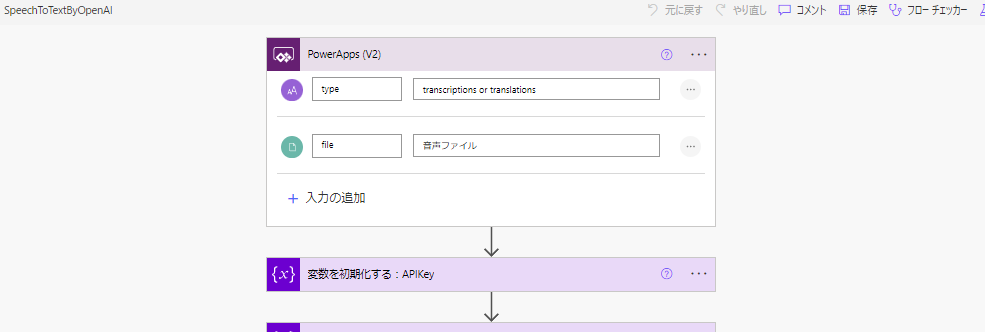
トリガーの引数は以下2つ。
- Appsから「音声」を入れてもらうファイル型の引数
- 「transcriptions(文字起こし)」か「translations(英語翻訳)」を選択してもらう文字列型の引数
次は「拡張子」と「MIMEタイプ」の対応定義を変数に作成。
※本当はもう少し対応しているファイルタイプがあるけど今回はこのくらいで。
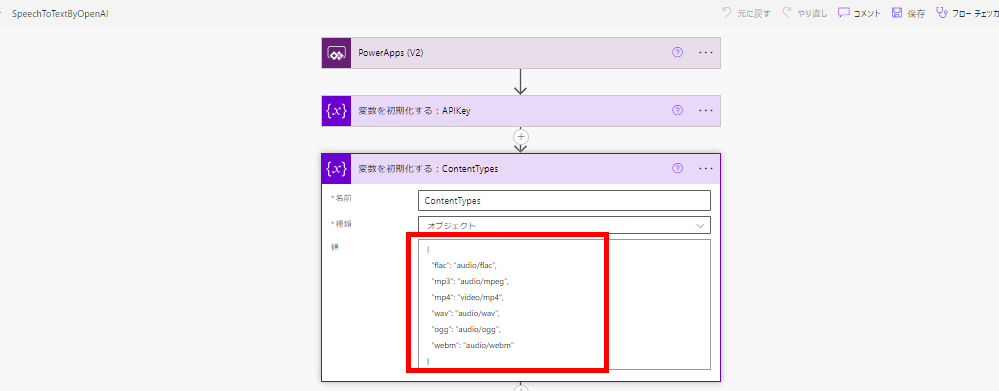
※本当はもう少し対応しているファイルタイプがあるけど今回はこのくらいで。
中身はこんな感じ。
{
"flac": "audio/flac",
"mp3": "audio/mpeg",
"mp4": "video/mp4",
"wav": "audio/wav",
"ogg": "audio/ogg",
"webm": "audio/webm"
}
そしたら引数で取得したファイルの拡張子から上で定義したMIMEタイプを取得する。
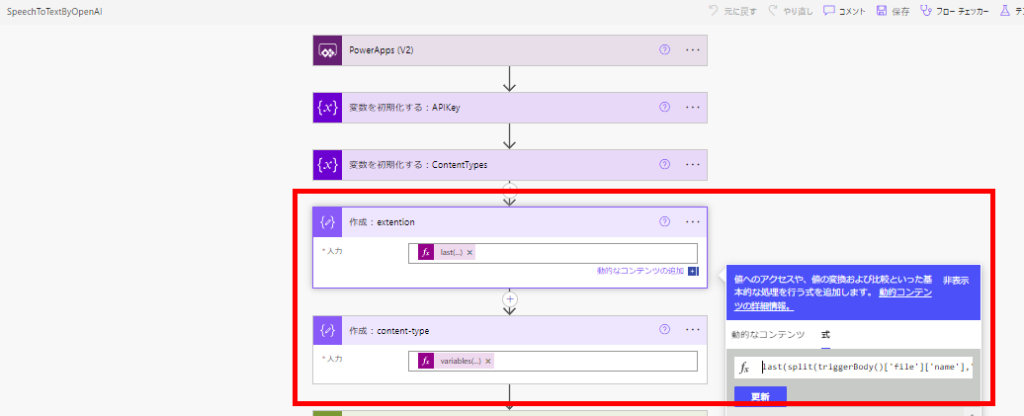
式はそれぞれこんな感じ。
// ファイル名からファイル拡張子の取得 last(split(triggerBody()['file']['name'],'.'))
// ファイル拡張子からMIMEタイプの取得
variables('ContentTypes')?[outputs('作成:extention')]
そしたらHTTPアクションでOpenAIのAPIをコールする。
※引数によって呼び出すURL(文字起こし or 英語翻訳)を変更。
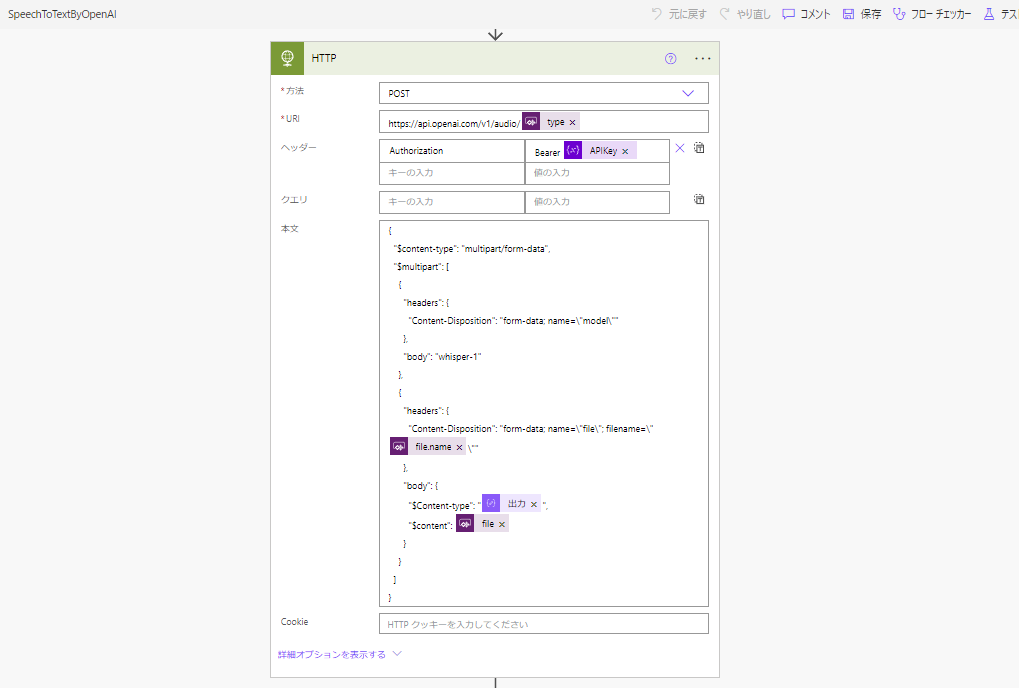
※引数によって呼び出すURL(文字起こし or 英語翻訳)を変更。
本文の中身はこちら。
{
"$content-type": "multipart/form-data",
"$multipart": [
{
"headers": {
"Content-Disposition": "form-data; name=\"model\""
},
"body": "whisper-1"
},
{
"headers": {
"Content-Disposition": "form-data; name=\"file\"; filename=\"@{triggerBody()['file']['name']}\""
},
"body": {
"$Content-type": "@{outputs('作成:content-type')}",
"$content": @{triggerBody()['file']['contentBytes']}
}
}
]
}
OpenAIからの返答はこんな感じの単純なJSONで返ってくるので、
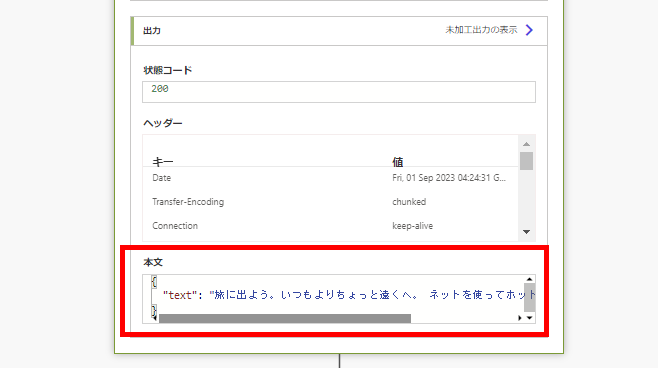
JSONを解析してあげて、中身をPower Appsへ戻す。
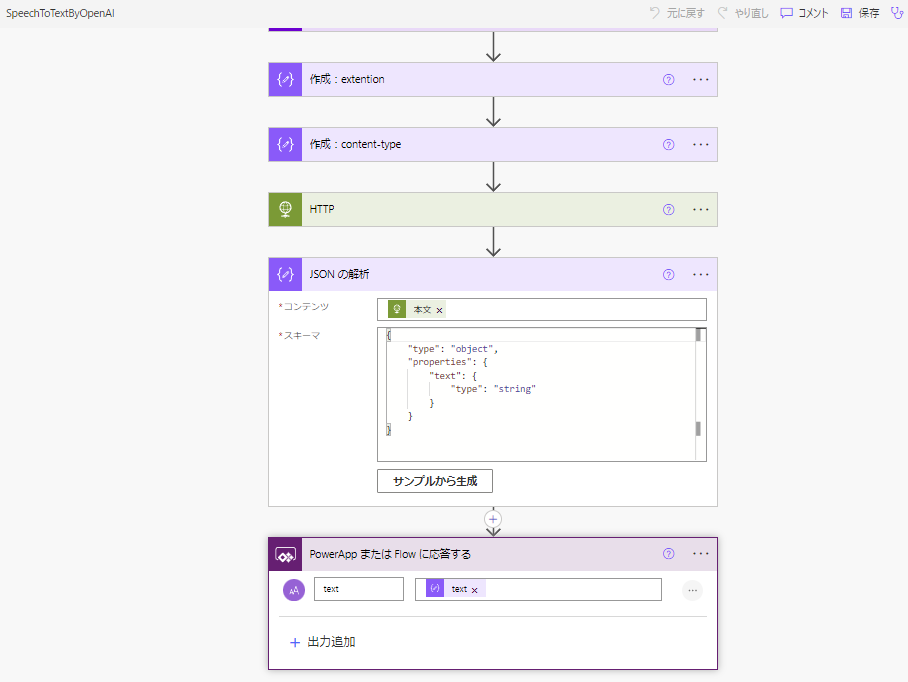
これでPower Automateは完成!
Power Appsの作成
呼び出し側のPower Appsは以下の2つを作成してみる。
- マイク(Microphone)コントロールから音声を渡す
- 添付ファイルコントロールから音声ファイルを渡す
マイク(Microphone)コントロールから音声を渡す
マイクコントロールから音声を渡す式はこんな感じ。
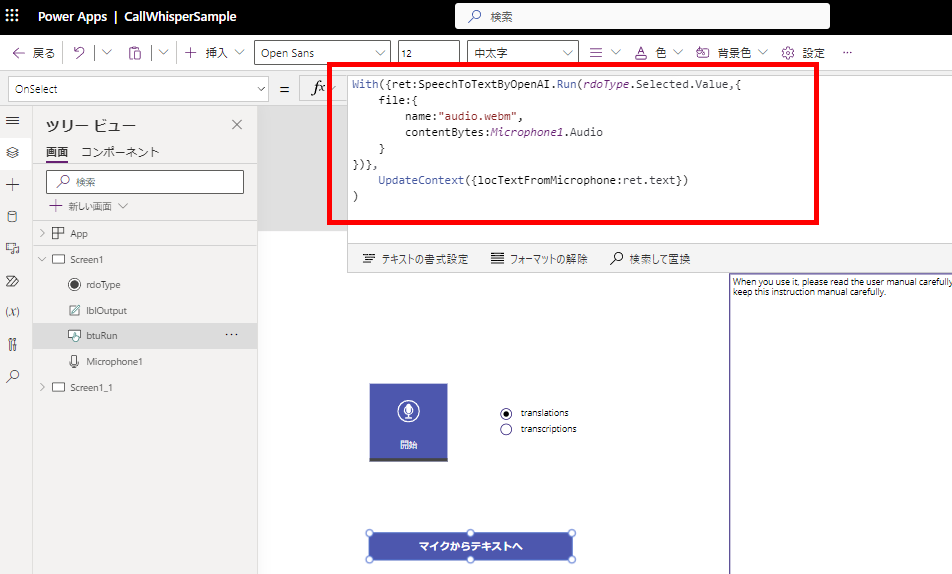
With({ret:SpeechToTextByOpenAI.Run(rdoType.Selected.Value,{
file:{
name:"audio.webm",
contentBytes:Microphone1.Audio
}
})},
UpdateContext({locTextFromMicrophone:ret.text})
)
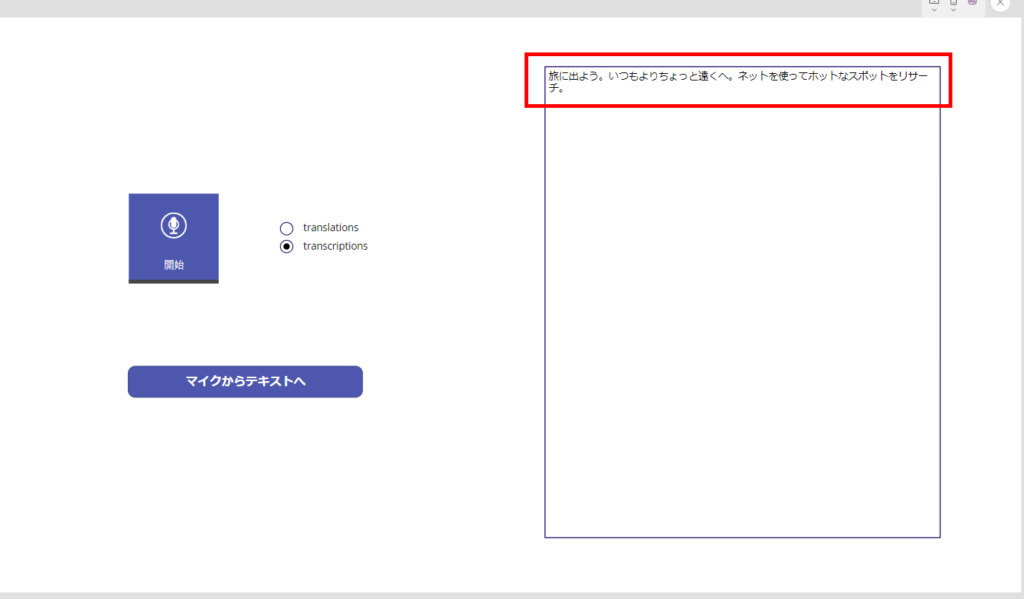
マイクコントロールで声を登録してPower Automateを呼び出すと、こんな感じで無事テキスト変換が成功する!
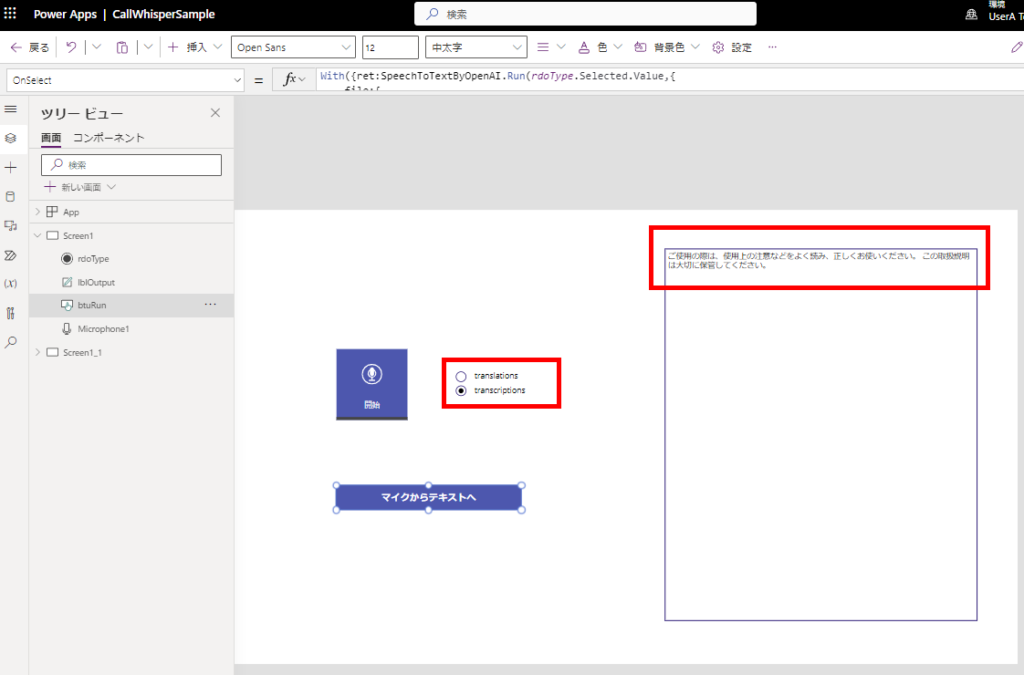
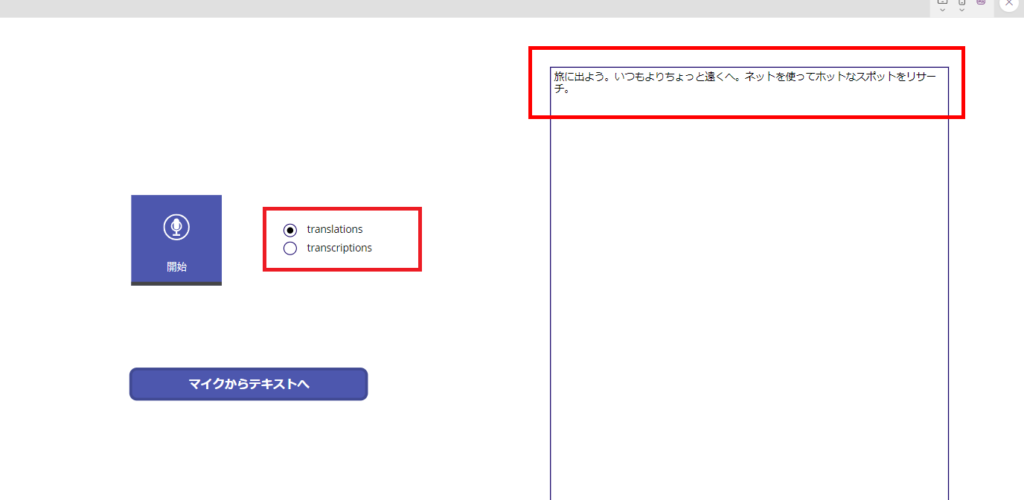
英語翻訳も無事成功!
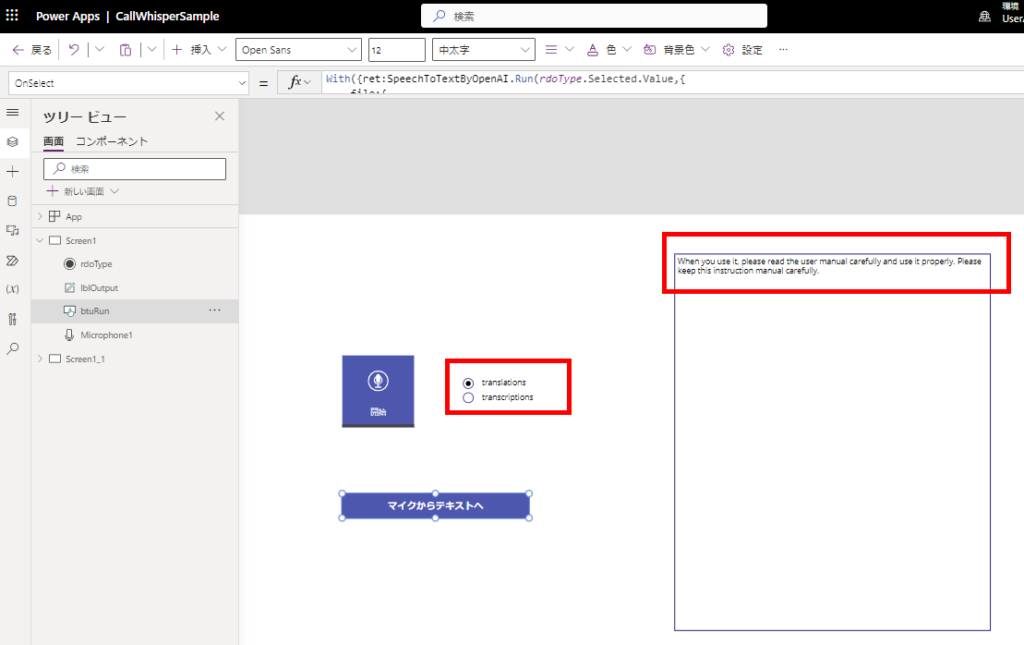
添付ファイルコントロールから音声ファイルを渡す
添付ファイルコントロールから音声ファイルを渡す場合はこんな感じ。
※添付ファイルの上限は1に設定。
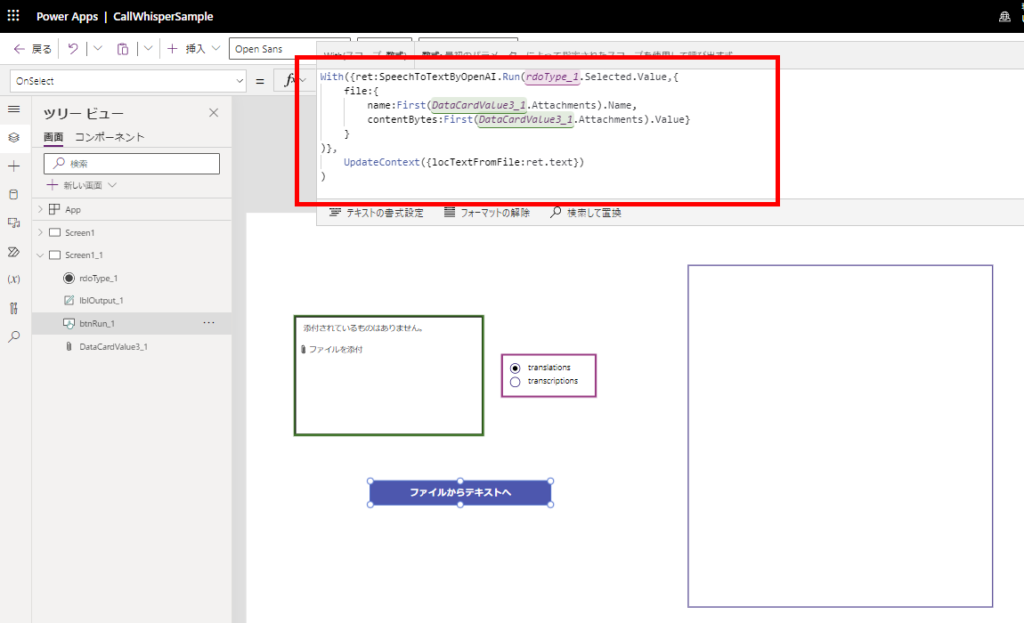
※添付ファイルの上限は1に設定。
With({ret:SpeechToTextByOpenAI.Run(rdoType_1.Selected.Value,{
file:{
name:First(DataCardValue3_1.Attachments).Name,
contentBytes:First(DataCardValue3_1.Attachments).Value}
})},
UpdateContext({locTextFromFile:ret.text})
)
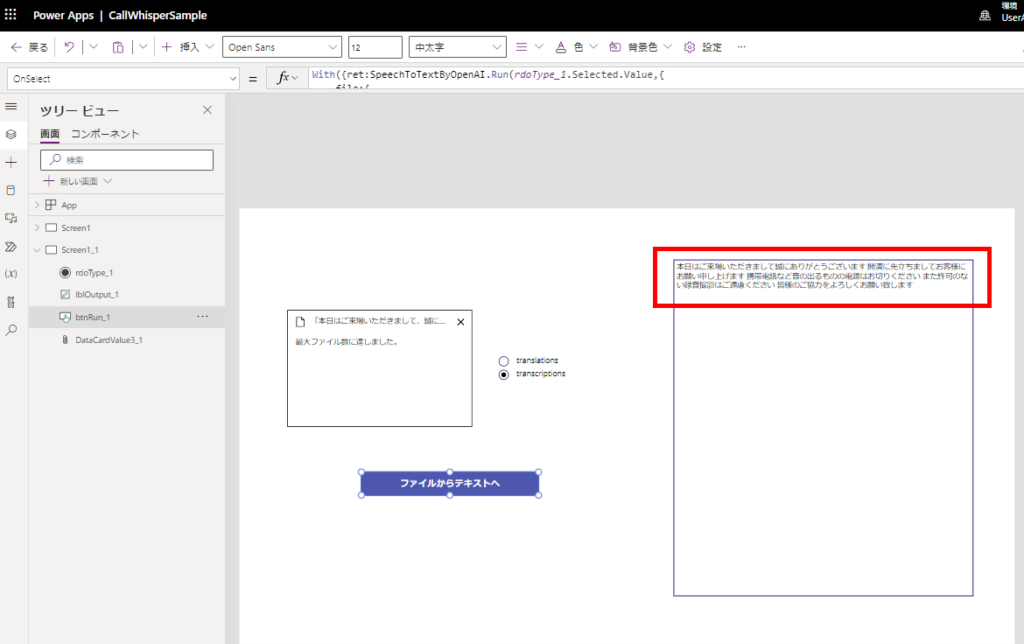
実際にファイルを添付してボタンを押してみると、
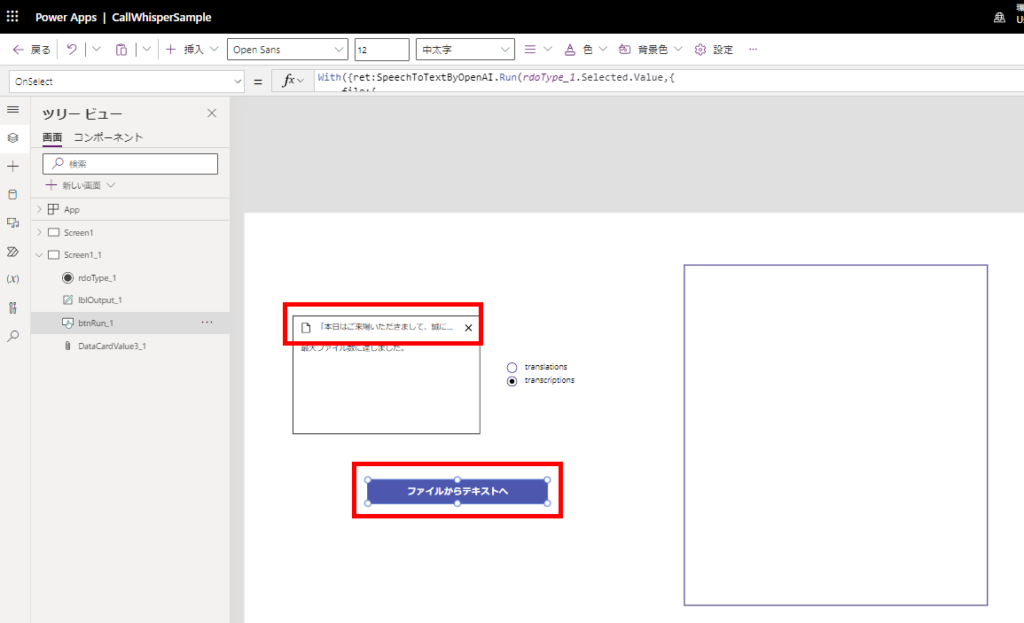
無事に動作!
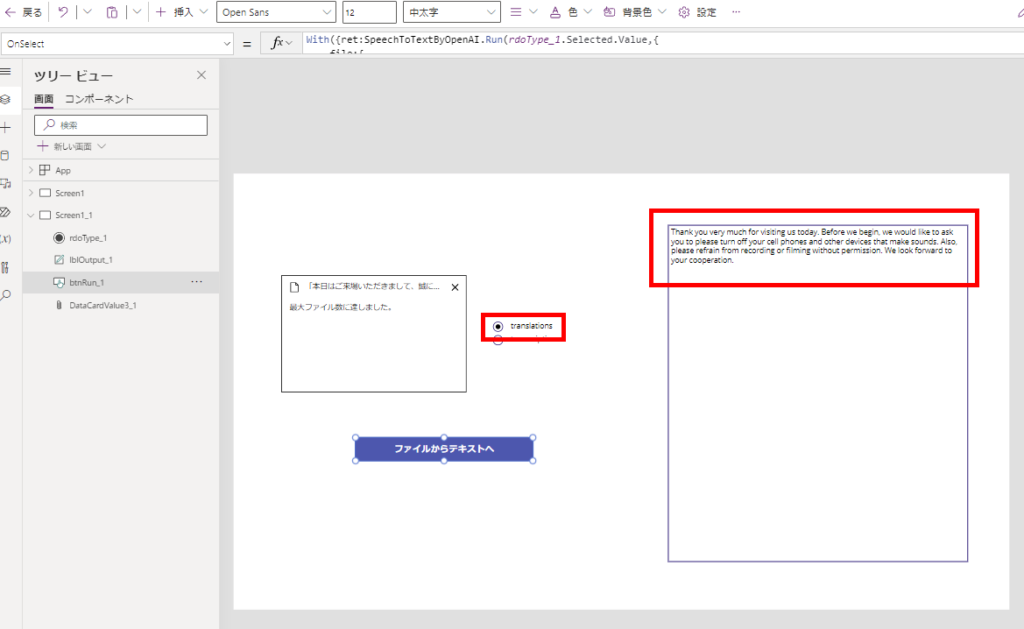
英語翻訳も無事動作!
※この記事ではこちらのサイト様の音声ファイルを使用させていただきました。
https://soundeffect-lab.info/sound/voice/info-lady1.html
おまけ1:日本語から英語への翻訳は失敗することも多い
友達に絵本の1ページを読んでみてもらったところ、
こんな感じで翻訳に失敗。ある程度固い文章じゃないとだめかもしれない。
おまけ2:ブラジル語はいけた
その友達がブラジル語も話せたのでせっかくだし録音してもらったら、文字起こし無事成功!
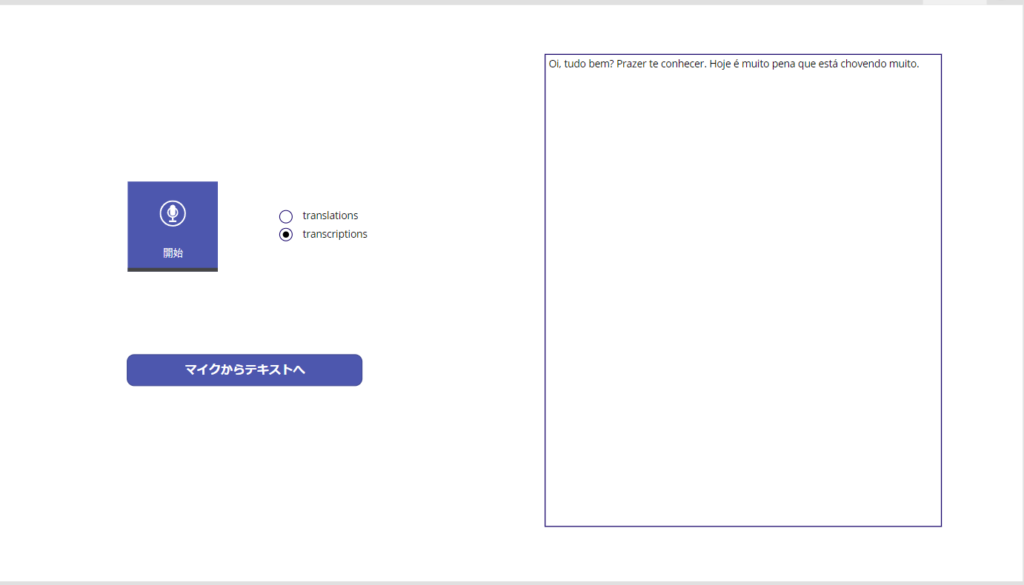
英語翻訳もできた!
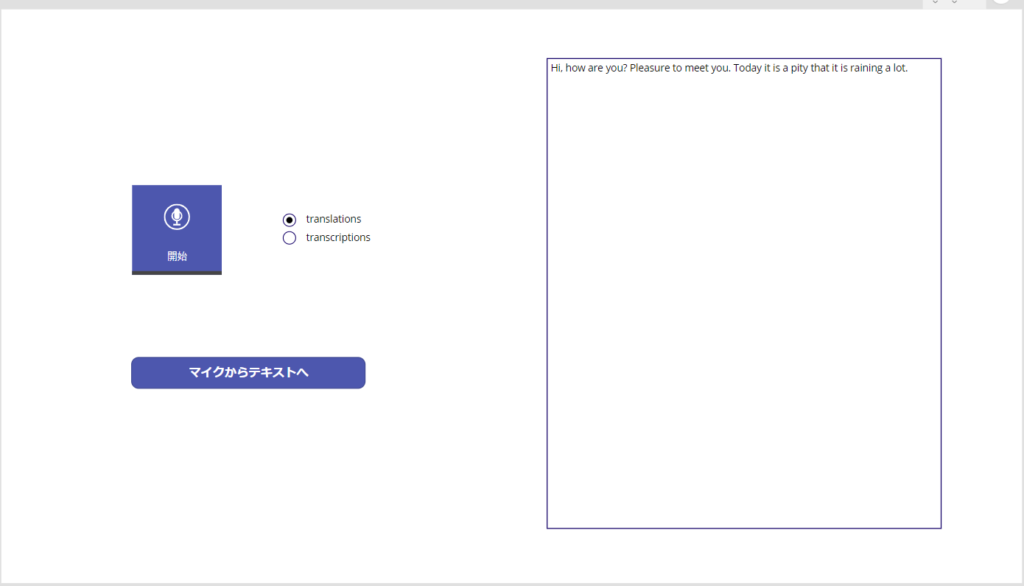
このAPIには引数として「prompt」や「temperature」「language」なども渡せるっぽいので、まだまだ色々遊べそう!

コメント