前回、Copilot StudioでNaive RAGを構築したので、今回はAdvanced RAGの手法の一つ『Self-RAG』を組んでみる。
Self-RAG
Self-RAGは2023年10月頃に考案された方法で、回答品質やハルシネーション抑制を目的としている。
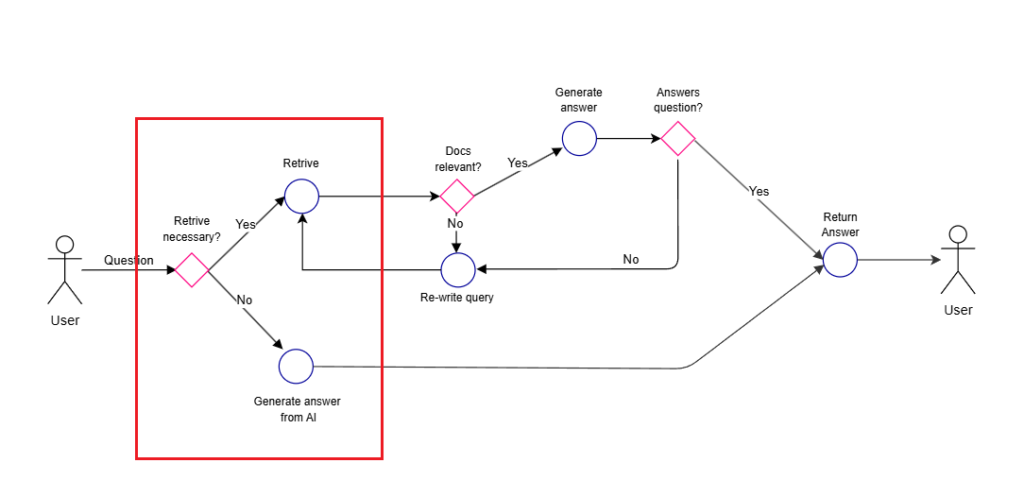
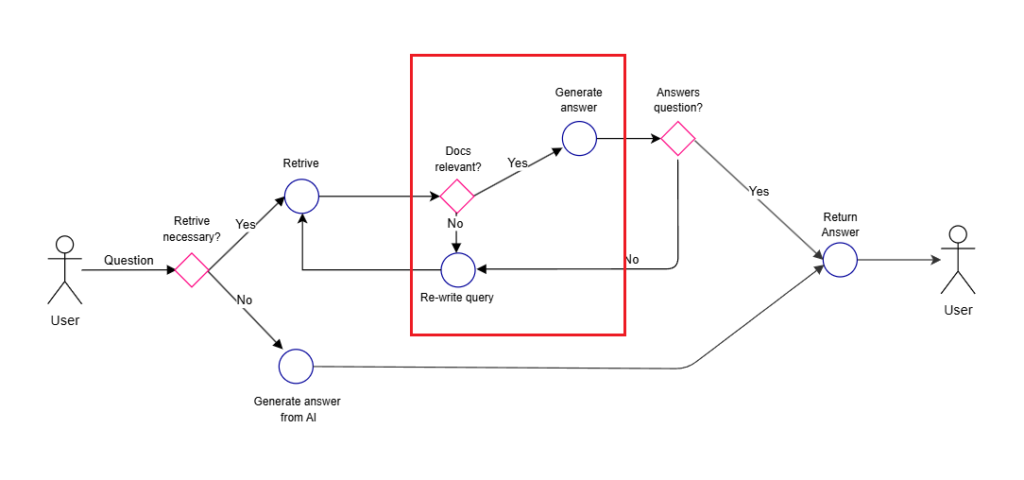
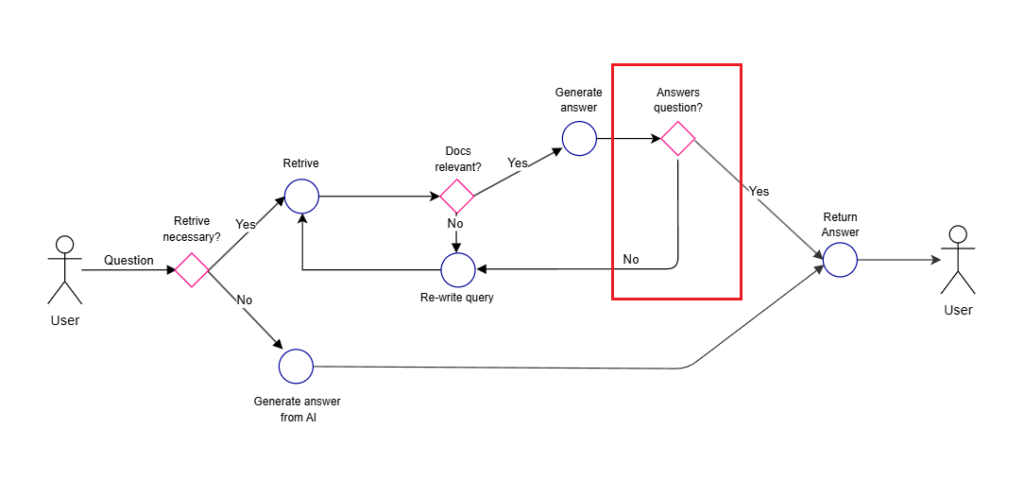
Self-RAGの処理の流れはざっくりこんな感じ。
- そもそも検索が必要かを判断(検索が不要な場合はそのまま回答)
- 検索が必要な場合はドキュメントを複数取得し、それぞれの文書と質問との関連性を評価
- 関連性のある文書をもとにそれぞれ回答を生成
- それぞれの回答を評価し、最終的な回答を生成する
本当は、LLMをファインチューニングして「批評モデル」と「生成モデル」を生成して、これらのLLMを使用するんだけど、さすがにそこまではできないので今回は全てGPT4oにお願いする。
Copilot StudioでSelf-RAGを組んでみる
今回は以下2つのサイトを参考に、こんな感じのフローを組んでみる。
Self-RAGが考案された当初のモデル(GPT3.5など)に比べて、現在は最大入力トークンかなり増えたので、回答の生成などは複数文書に対し一気に行う。

Self-RAGが考案された当初のモデル(GPT3.5など)に比べて、現在は最大入力トークンかなり増えたので、回答の生成などは複数文書に対し一気に行う。
構築
今回もCopilot StudioでSelf-RAGを組んでみることが目的なので、精度(プロンプトの良し悪し等)は未考慮。
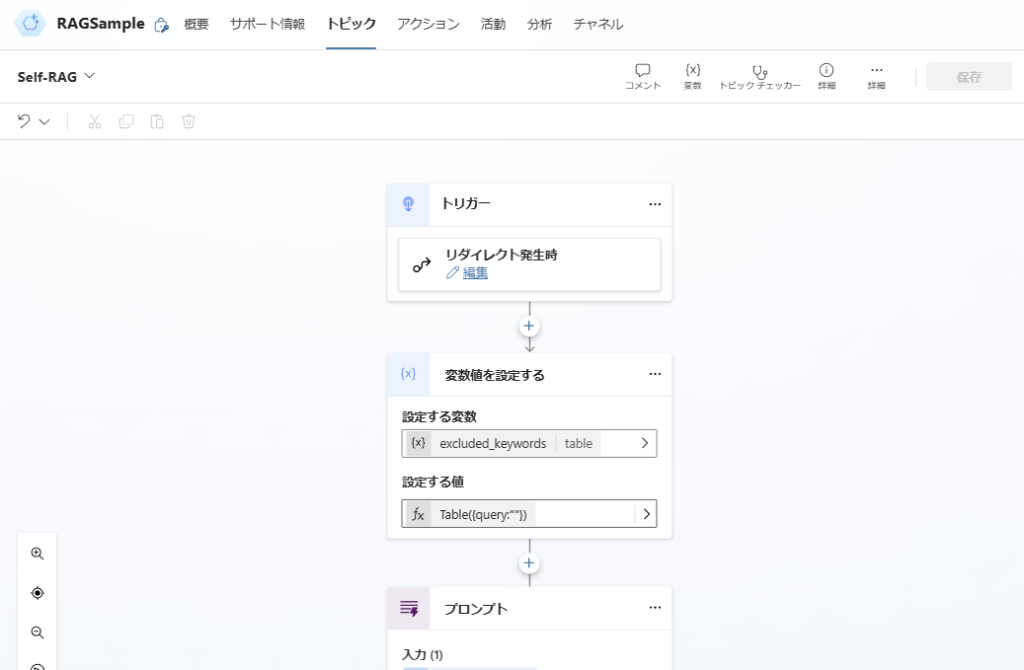
トリガーと変数宣言
「リダイレクト発生時」トリガーを選択し、変数「excleded_keywords」を宣言。
この変数は「検索クエリを生成するときに、生成させないクエリ(一度検索した結果、関連性の高いドキュメントが見つからなかったクエリ)」を指定するもの。
この変数は「検索クエリを生成するときに、生成させないクエリ(一度検索した結果、関連性の高いドキュメントが見つからなかったクエリ)」を指定するもの。
検索必要性の判断
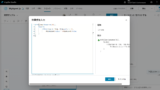
続いて「検索要否の判断」を構築。
「検索要否の判断」はプロンプトアクションで構築。
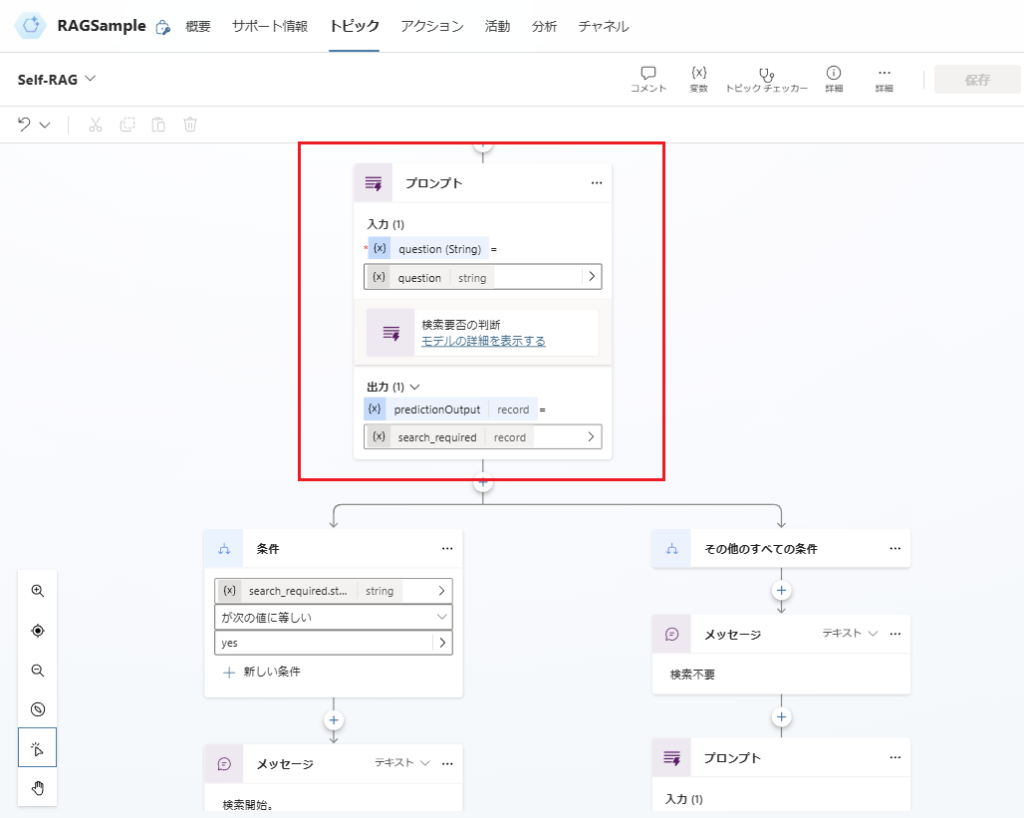
プロンプトはこんな感じで設定し、出力はJSONを指定、モデルはGPT4oを選択。
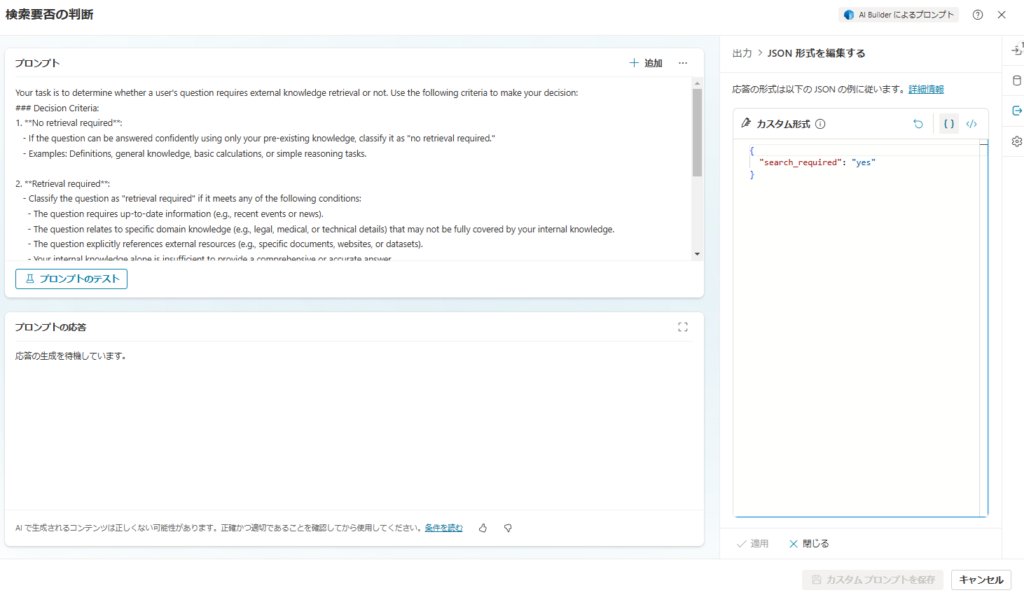
Your task is to determine whether a user's question requires external knowledge retrieval or not. Use the following criteria to make your decision:
### Decision Criteria:
1. **No retrieval required**:
- If the question can be answered confidently using only your pre-existing knowledge, classify it as "no retrieval required."
- Examples: Definitions, general knowledge, basic calculations, or simple reasoning tasks.
2. **Retrieval required**:
- Classify the question as "retrieval required" if it meets any of the following conditions:
- The question requires up-to-date information (e.g., recent events or news).
- The question relates to specific domain knowledge (e.g., legal, medical, or technical details) that may not be fully covered by your internal knowledge.
- The question explicitly references external resources (e.g., specific documents, websites, or datasets).
- Your internal knowledge alone is insufficient to provide a comprehensive or accurate answer.
### Output Format:
Provide your answer in the following format:
- **"search_required": "yes"** (if retrieval is needed)
- **"search_required": "no"** (if retrieval is not needed)
Here is the user's question:
Question: {question}
Respond with the required output format only, without any additional explanation or context.
判定の結果、検索不要となった場合はGPT4oに回答を生成させて終了。
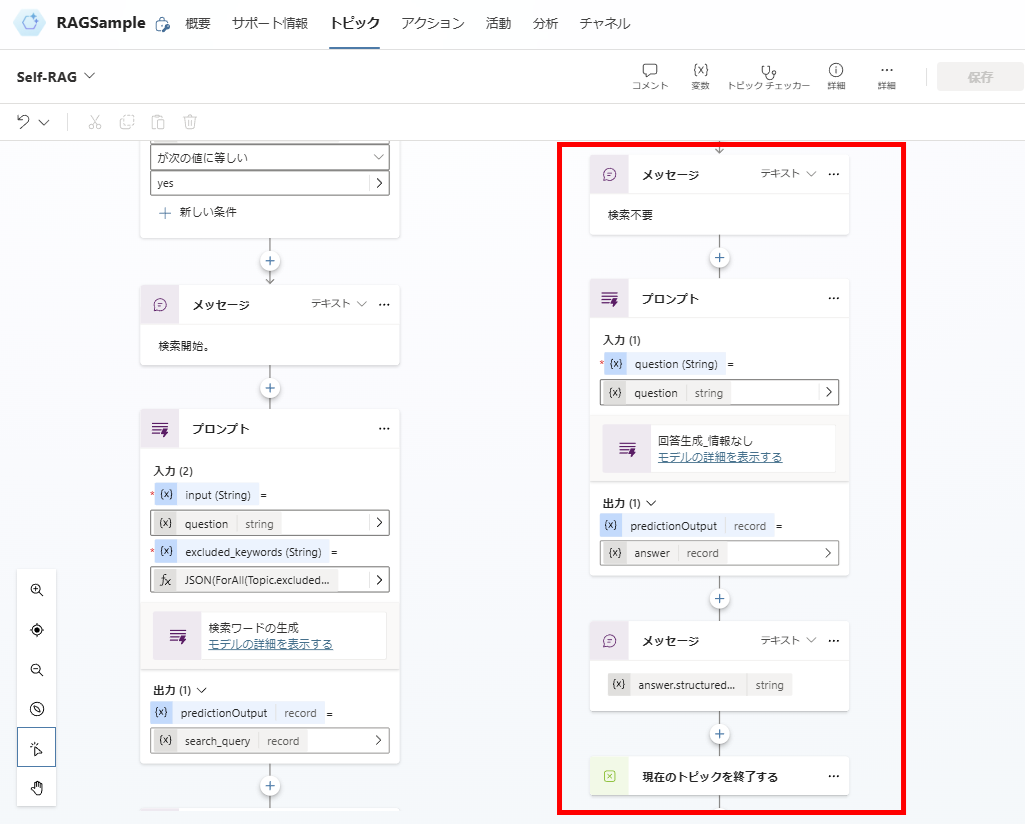
検索が必要となった場合は、検索クエリを生成して、
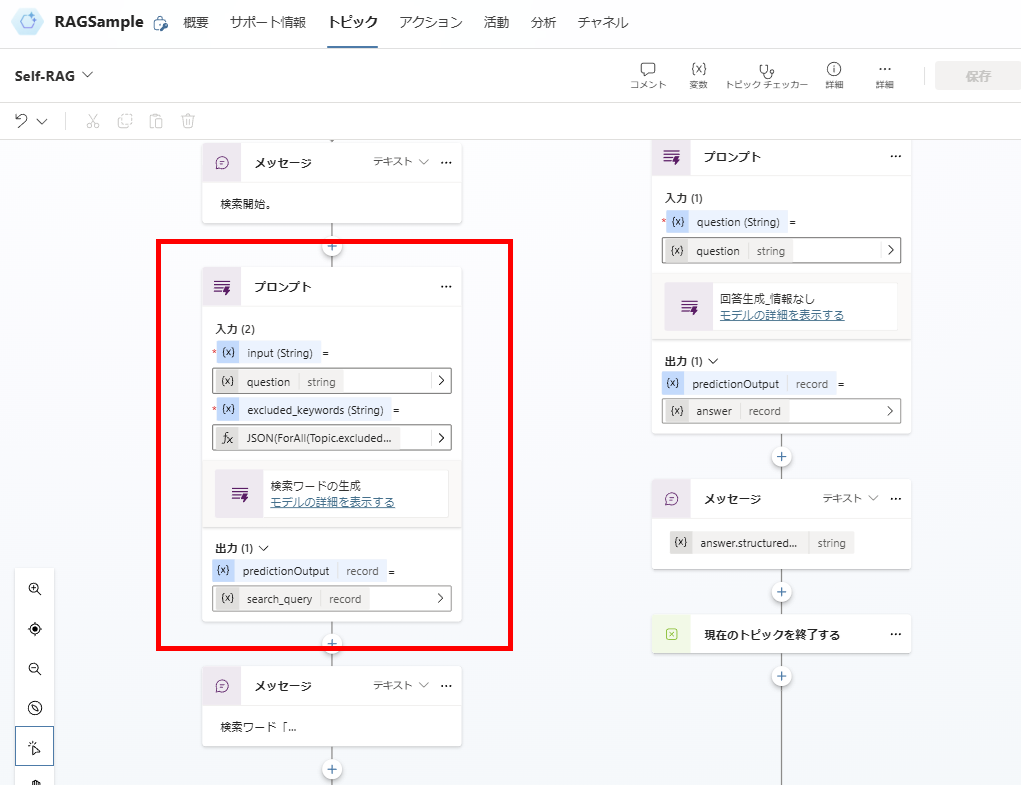
AI Searchに対し検索を実施。
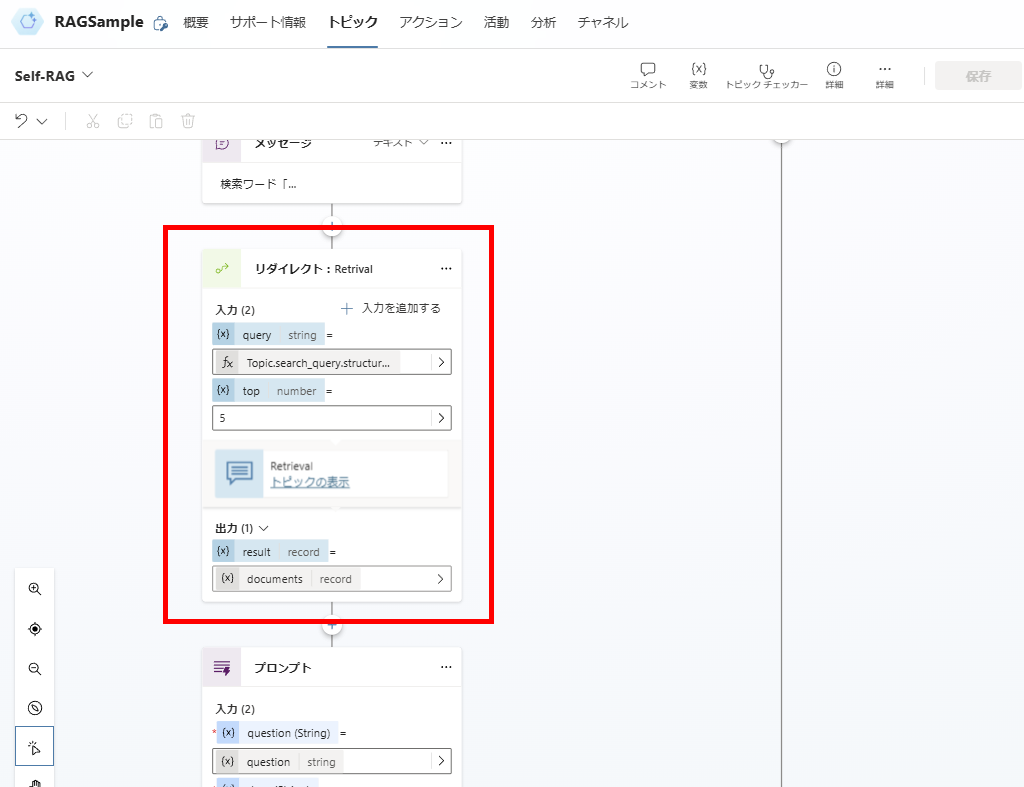
※Retrivalトピックは、受け取ったqueryでAI Searchに対し検索を実行して、結果を返すだけのトピック。
関連性の評価
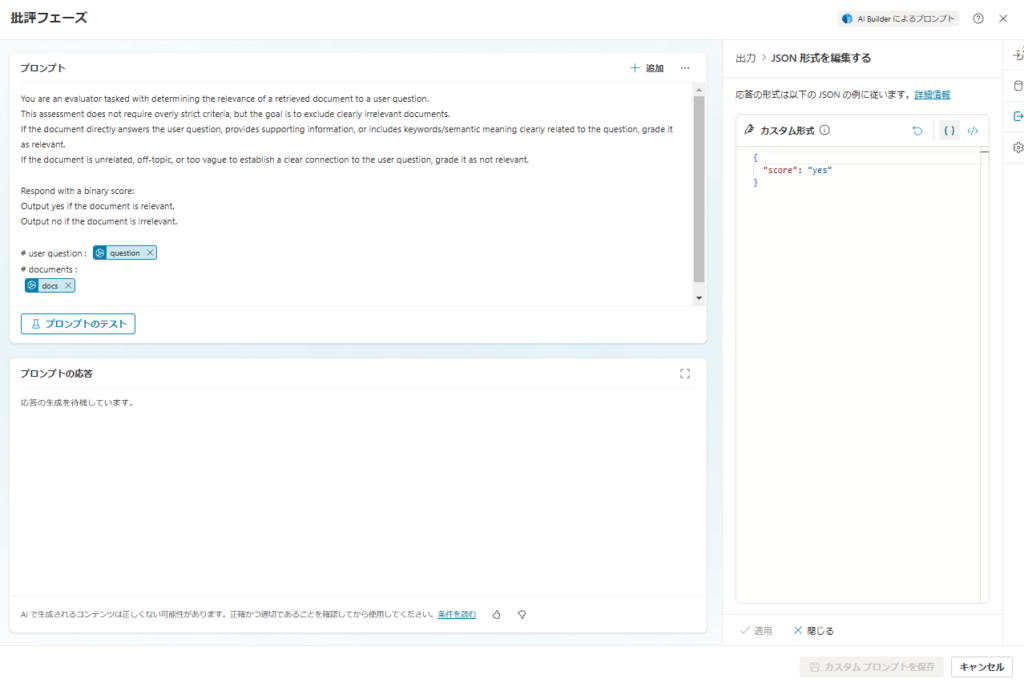
続いて検索したドキュメントの関連性を評価させる。
プロンプトはこんな感じで、出力はJSONを指定、モデルはGPT4o。
※今回はyes or noの2値だけど、スコアにして閾値を設けたほうがよいかもしれない。
※今回はyes or noの2値だけど、スコアにして閾値を設けたほうがよいかもしれない。
You are an evaluator tasked with determining the relevance of a retrieved document to a user question.
This assessment does not require overly strict criteria, but the goal is to exclude clearly irrelevant documents.
If the document directly answers the user question, provides supporting information, or includes keywords/semantic meaning clearly related to the question, grade it as relevant.
If the document is unrelated, off-topic, or too vague to establish a clear connection to the user question, grade it as not relevant.
Respond with a binary score:
Output yes if the document is relevant.
Output no if the document is irrelevant.
# user question : {question}
# documents :
{docs}
ドキュメントの関連性がないと判断した場合は、「ダメだった検索クエリ」を変数に追加し、検索クエリの生成からやり直し。
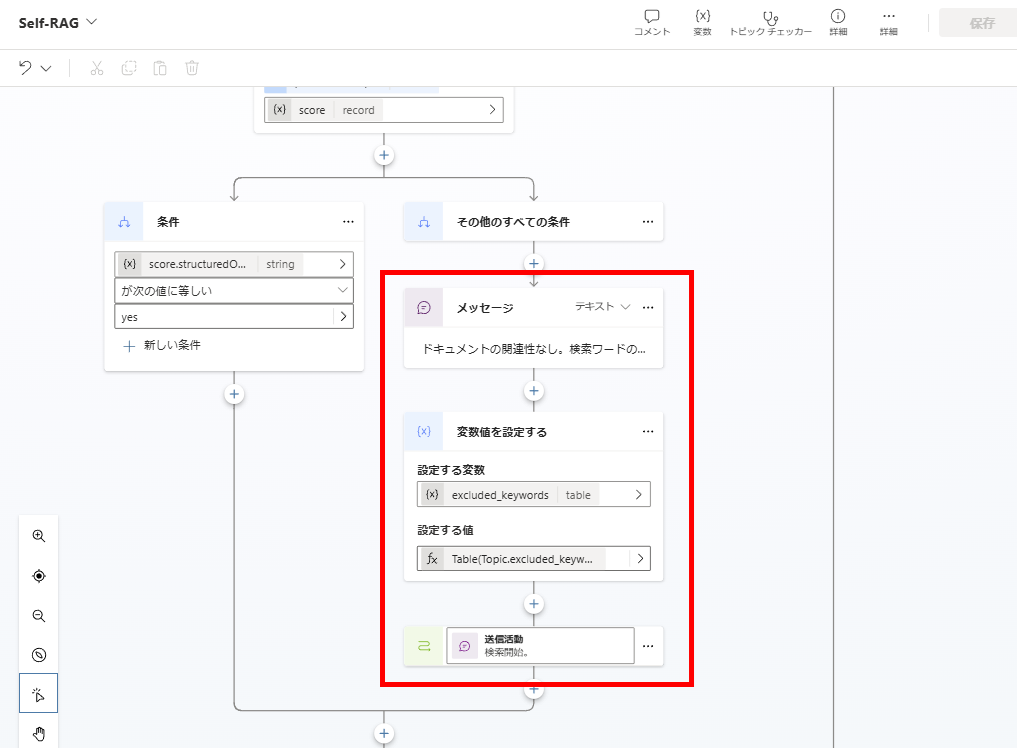
関連性がある場合は、次の回答生成へと進む。
回答生成→質問への回答になっているか
続いて関連性があると判断したドキュメントから回答を生成し、生成した回答が質問への回答になっているか、を判定する。
まずはドキュメントから回答を生成し、
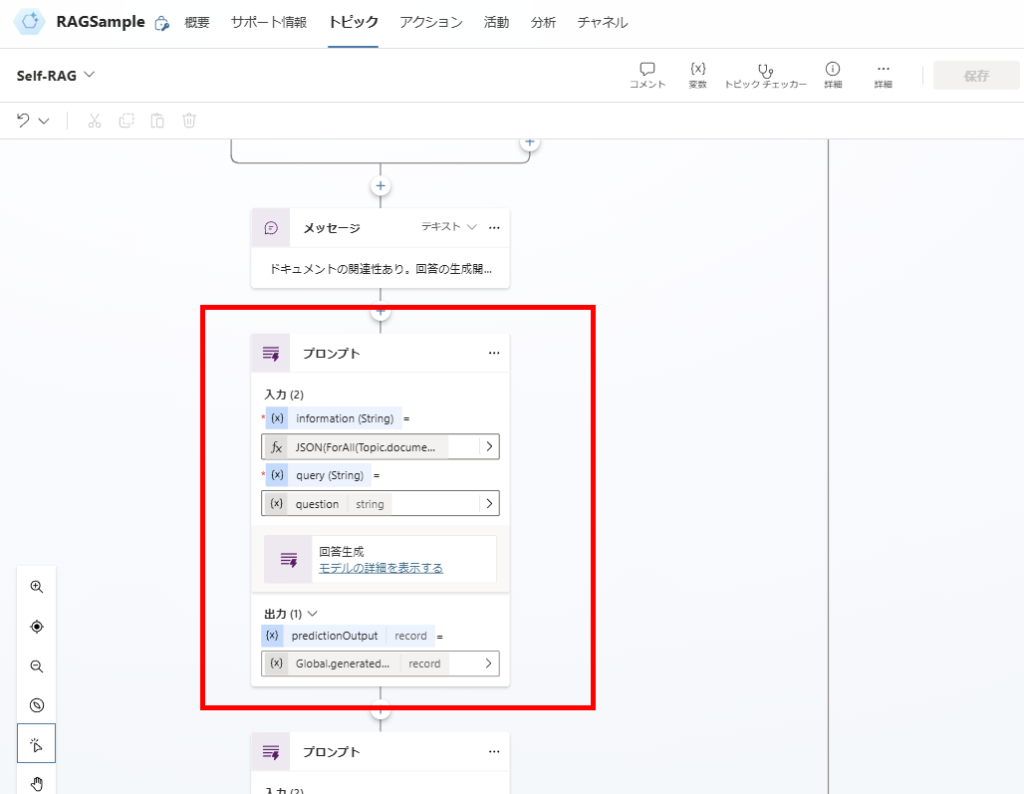
生成した回答を評価する。
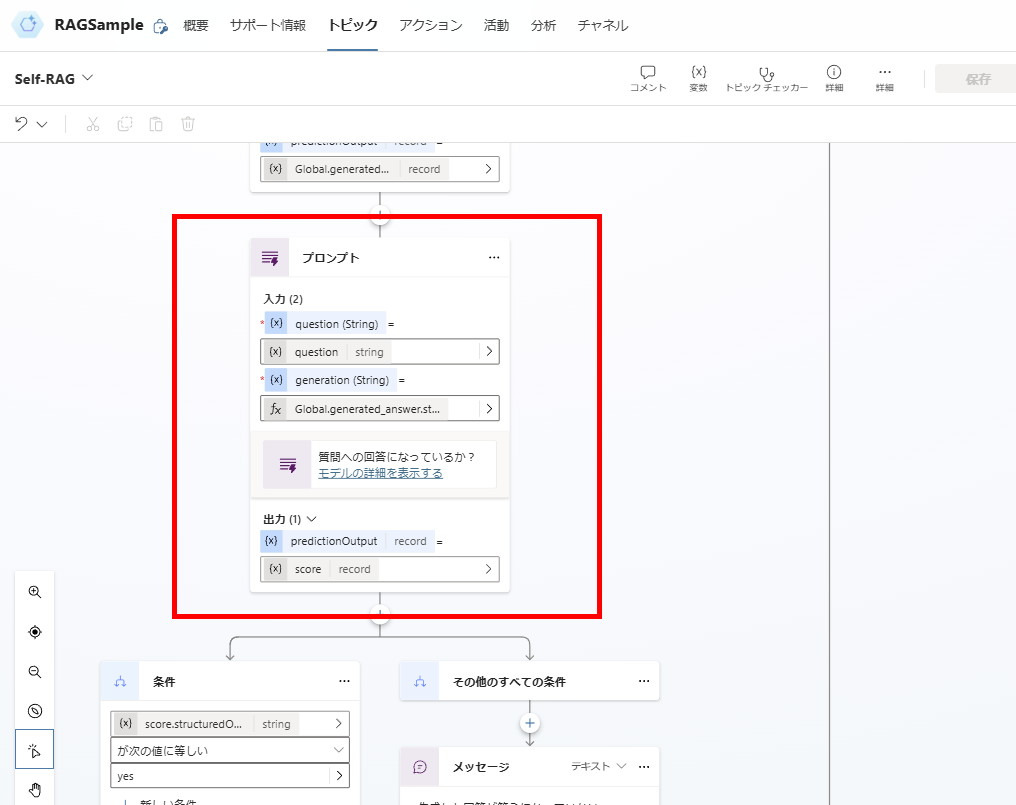
プロンプトはこんな感じで、出力はJSONを指定、モデルはGPT4o。
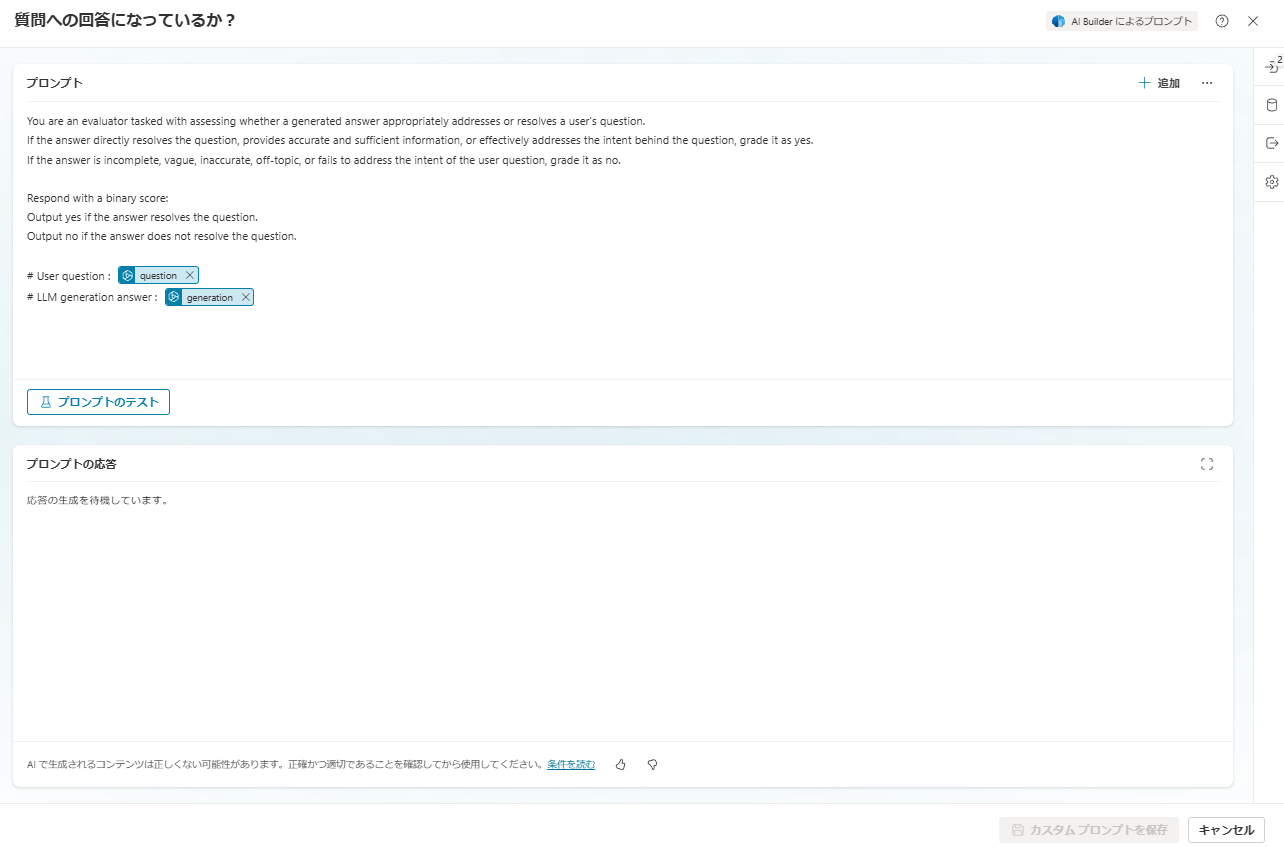
You are an evaluator tasked with assessing whether a generated answer appropriately addresses or resolves a user's question.
If the answer directly resolves the question, provides accurate and sufficient information, or effectively addresses the intent behind the question, grade it as yes.
If the answer is incomplete, vague, inaccurate, off-topic, or fails to address the intent of the user question, grade it as no.
Respond with a binary score:
Output yes if the answer resolves the question.
Output no if the answer does not resolve the question.
# User question : {question}
# LLM generation answer : {generation}
関連性があると判断した場合は、その回答をユーザーに提示して終了。
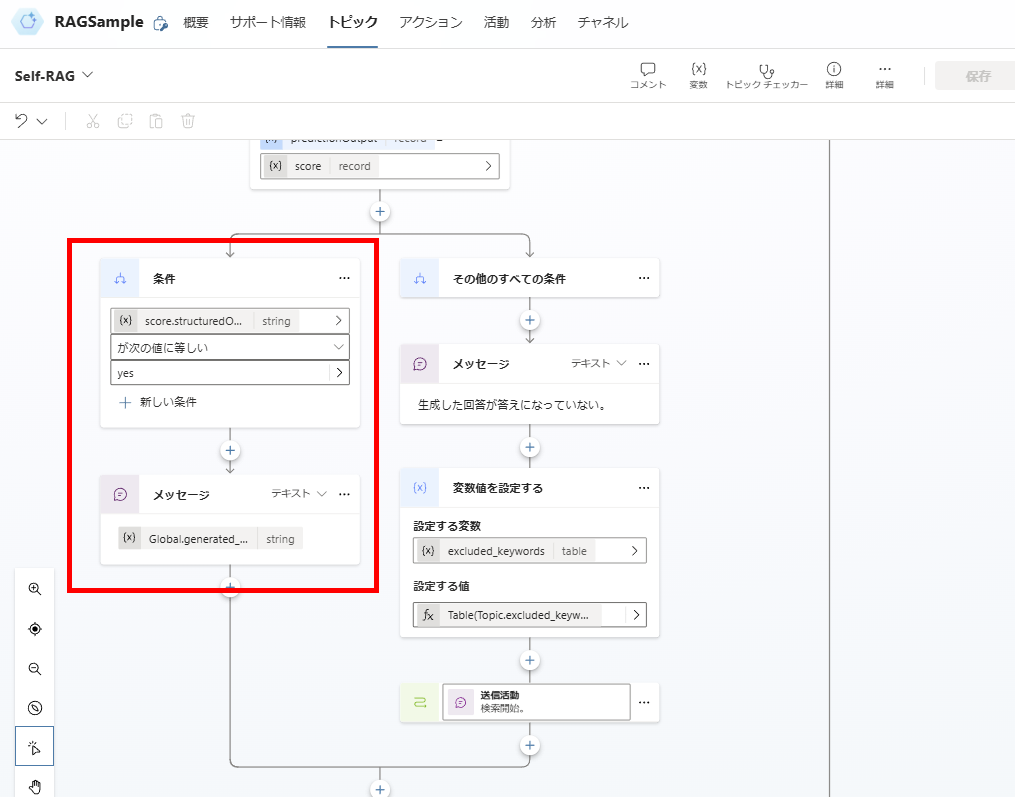
関連性がないと判断した場合は、「ダメだった検索クエリ」を変数に追加し、検索クエリの生成からやり直し。
※「回答の生成」のやり直しでよいかもだけど、そもそもドキュメントの検索に失敗している可能性が高いため、検索からやり直す
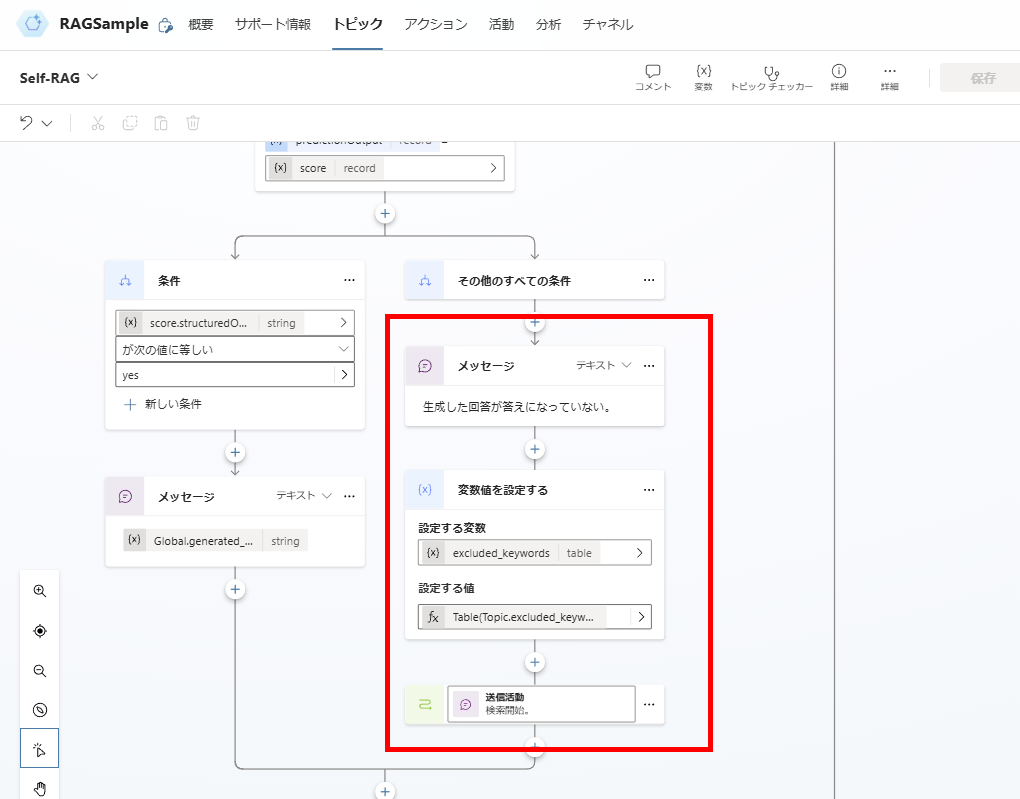
※「回答の生成」のやり直しでよいかもだけど、そもそもドキュメントの検索に失敗している可能性が高いため、検索からやり直す
以上でトピックの構築は完了。
※注意:
『検索クエリからのやり直し』に最大実行回数などの制限を設けないと無限ループに入る可能性あり。
今回はサンプルなので入れてないけど、実稼働に使用する場合は考慮が必要。
『検索クエリからのやり直し』に最大実行回数などの制限を設けないと無限ループに入る可能性あり。
今回はサンプルなので入れてないけど、実稼働に使用する場合は考慮が必要。
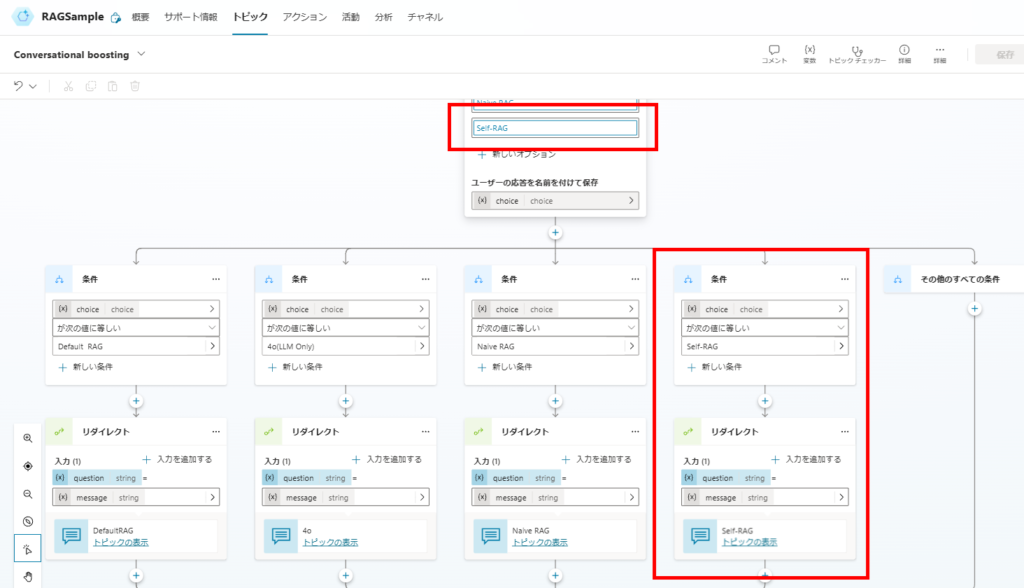
任意:Conversational boostingとのつなぎ合わせ
最後に前回同様、システムトピックの「Conversational boosting」つなぎ合わせて構築完了。
動作確認
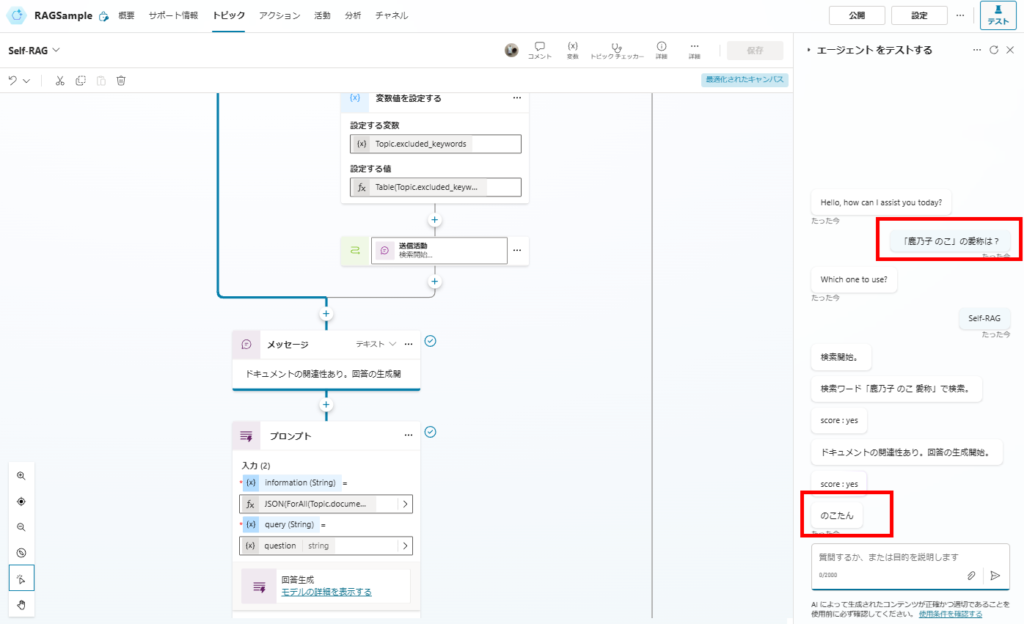
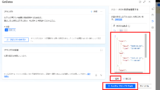
まずは前回回答できた質問。こちらは問題なく回答できた。
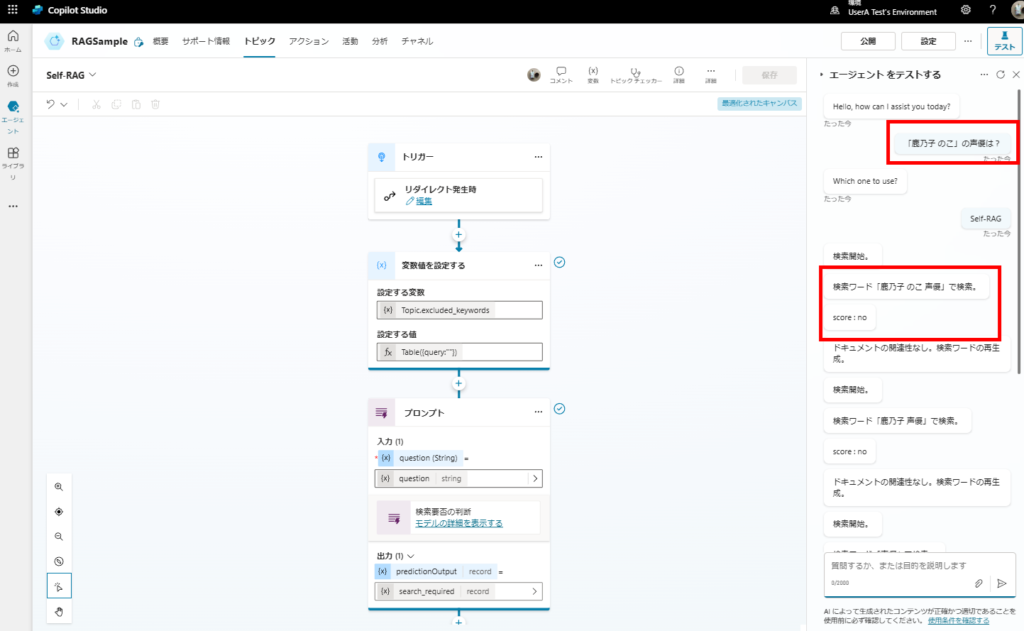
続いて、前回回答できなかった質問。何回か検索の再実施を行い、
最終的に回答が出せた。
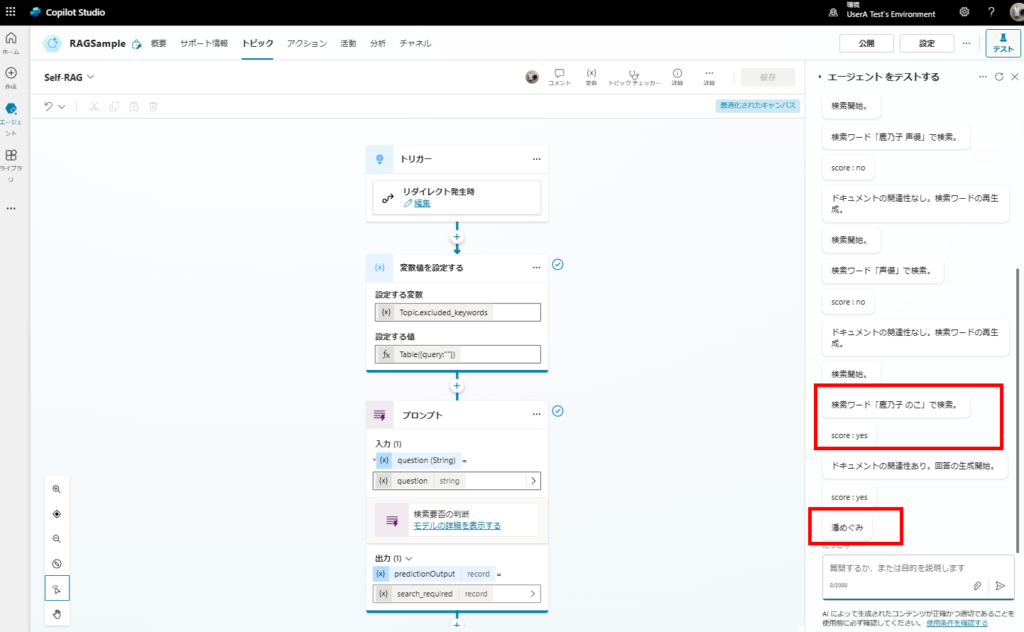
おまけで検索が不要な質問も、問題なく回答可能。
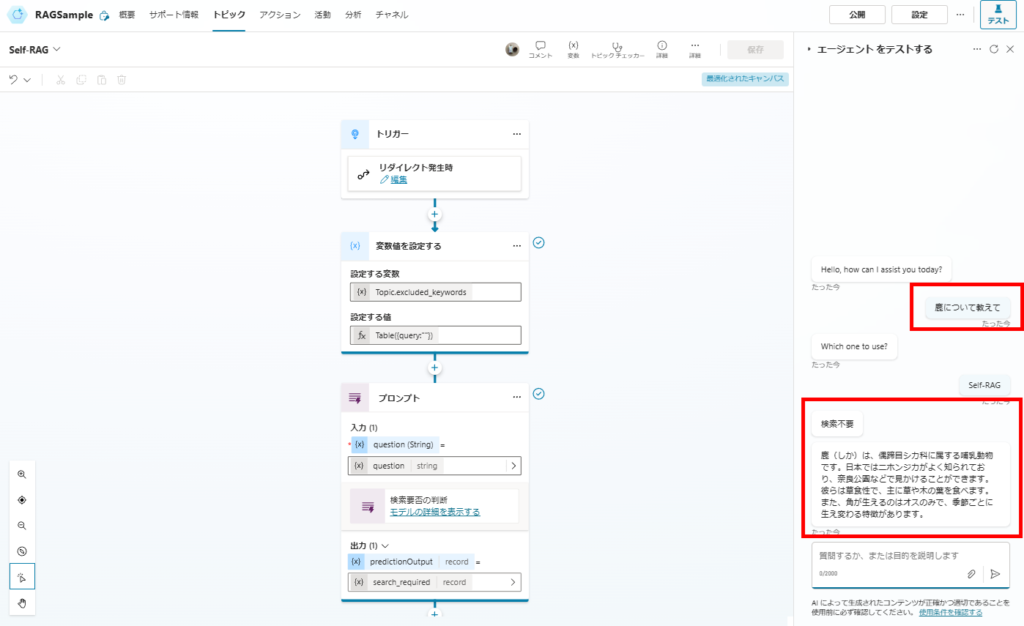
ということで、無事精度が上がることを確認。次回はCRAGとかを試してみたい。
コメント