In this tutorial, we implement a Corrective Retrieval Augmented Generation (CRAG) system using Copilot Studio and AI Search. This builds upon our previous guide on Self-RAG implementation.
What is CRAG?
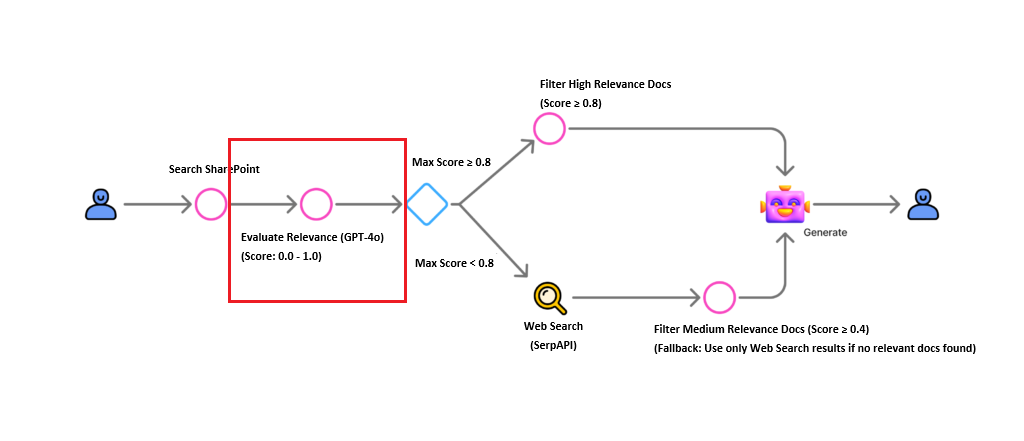
Proposed in early 2024, CRAG (Corrective Retrieval Augmented Generation) is an advanced RAG technique designed to significantly reduce hallucinations compared to traditional methods. Its core innovation lies in using a Retrieval Evaluator to assess the relevance of retrieved documents before generating an answer.
Retrieval Evaluation Workflow
- Correct (Highly Relevant): Generate response using retrieved documents directly.
- Incorrect (Low Relevance): Discard documents and fallback to web search.
- Ambiguous: Combine retrieved documents with web search results for a comprehensive answer.
Architecture Overview
Below is the workflow we will implement. We utilize GPT-4o for relevance evaluation and SerpAPI for web search capabilities.
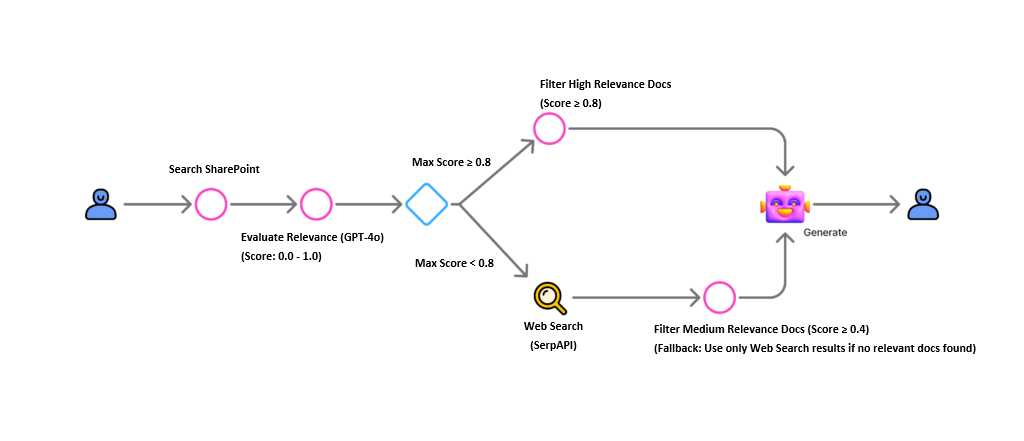
Step-by-Step Implementation
Our goal is to demonstrate the architectural implementation of CRAG within Copilot Studio.
1. SharePoint Search Setup
First, we configure the initial document retrieval from SharePoint.
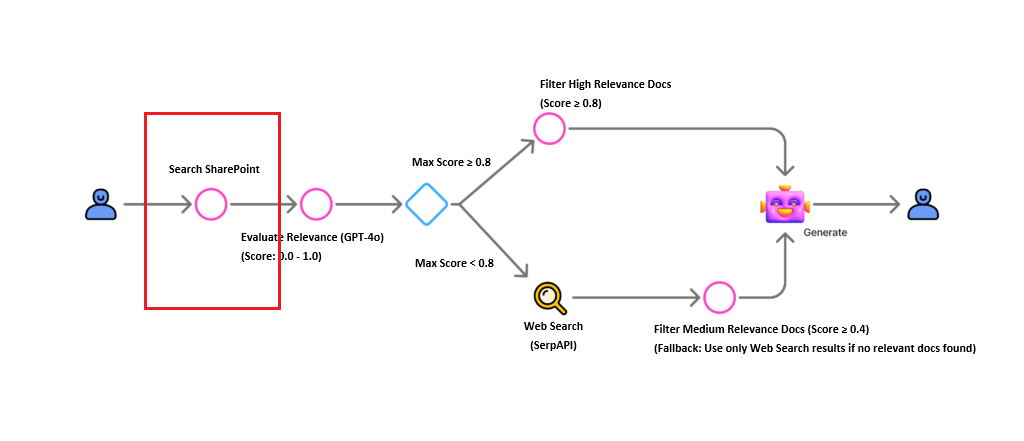
We use a prompt action to transform the user’s natural language question into an optimized search query.
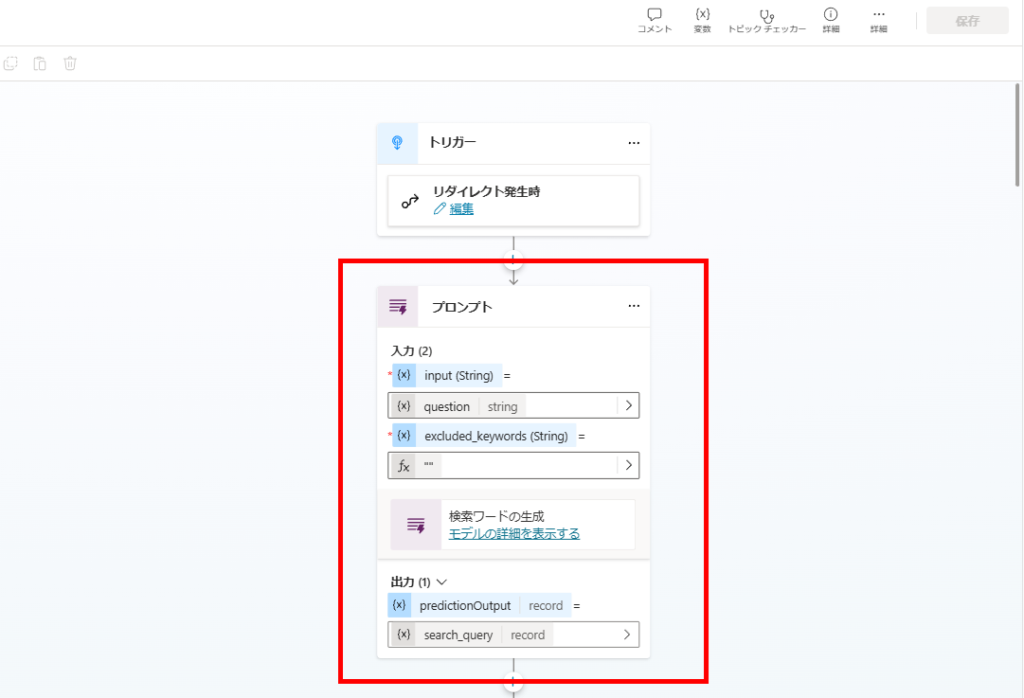
The prompt configuration (reused from our Self-RAG implementation) ensures keywords are extracted effectively.
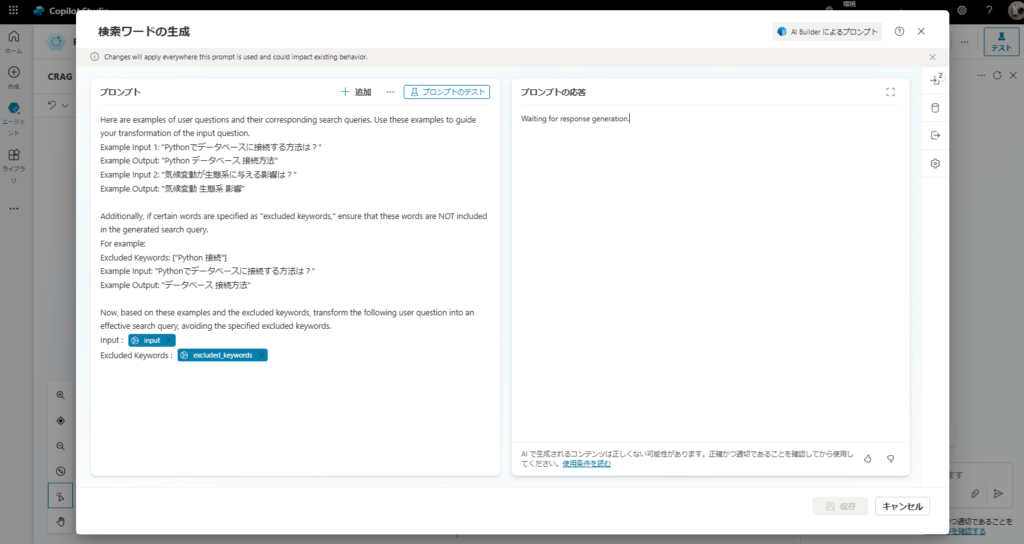
Here are examples of user questions and their corresponding search queries. Use these examples to guide your transformation of the input question.
Example Input 1: "How to connect to a database with Python?"
Example Output: "Python database connection method"
Additionally, if certain words are specified as "excluded keywords," ensure that these words are NOT included in the generated search query.
Input: {input}
Excluded Keywords: {excluded_keywords}
Using the generated query, we execute a search against SharePoint via Azure AI Search.
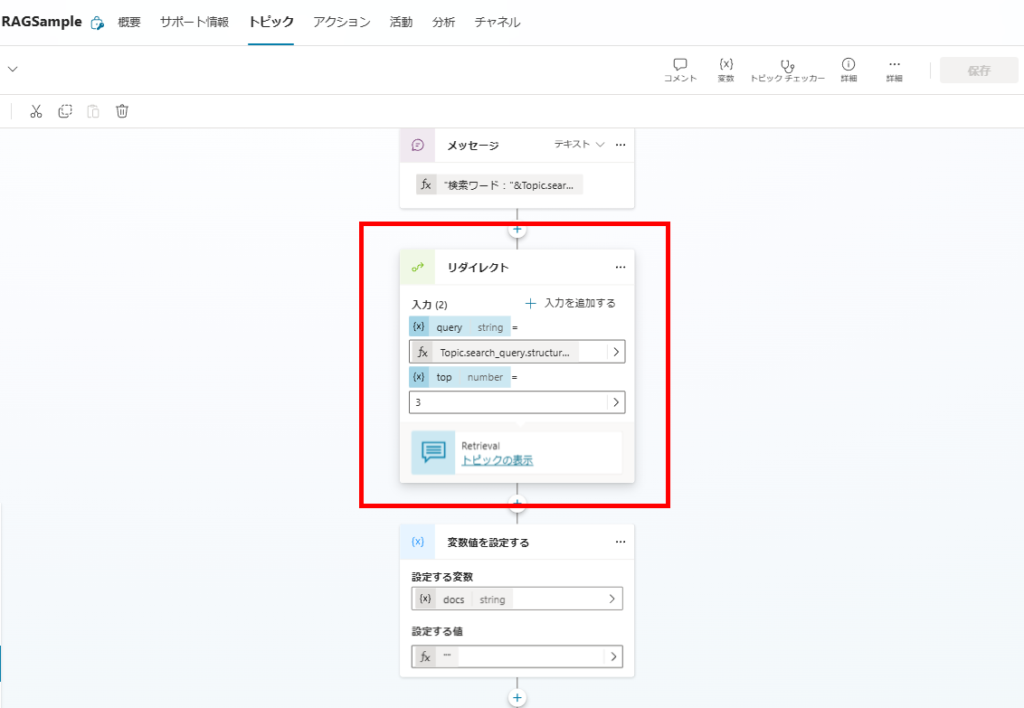
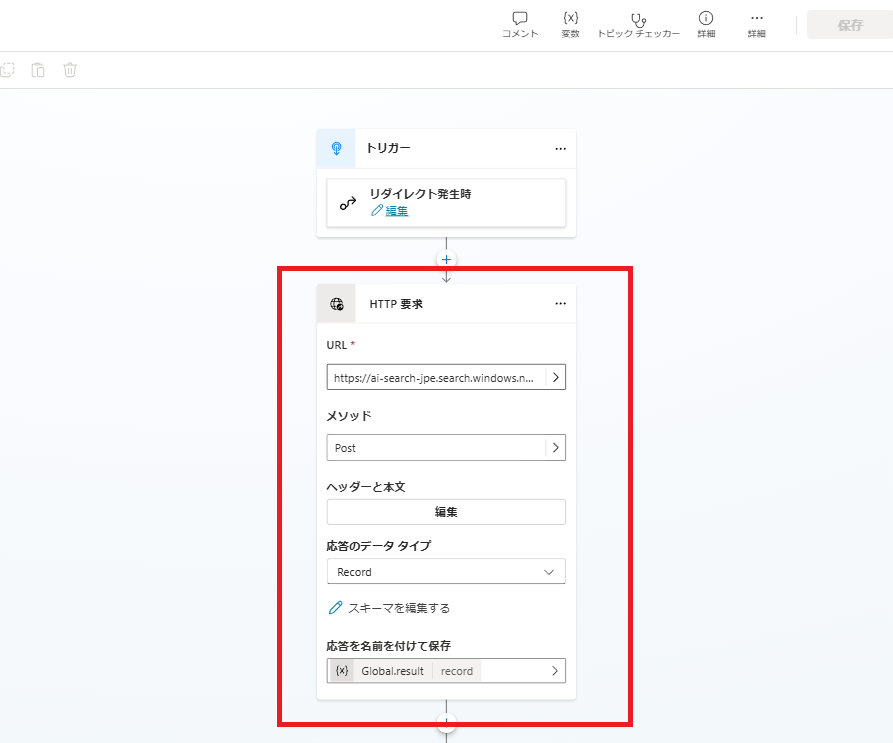
For detailed AI Search setup instructions, refer to our SharePoint Search Guide.
2. Document Relevance Evaluation
Next, we score the relevance of each retrieved document against the user’s question.
We iterate through all search results using a For Each loop.
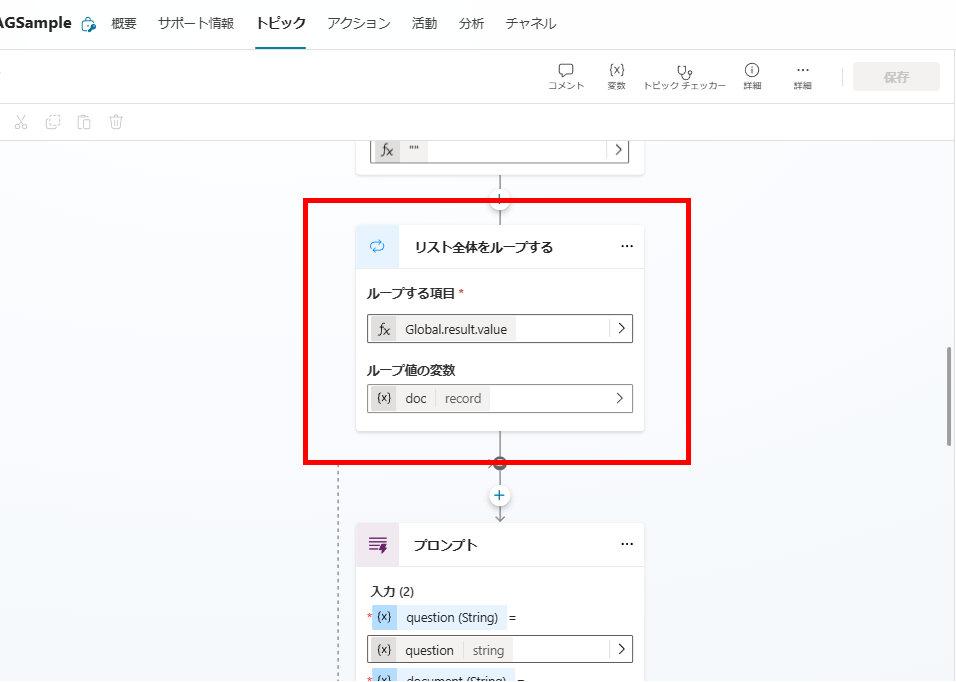
Inside the loop, a GPT-4o prompt assigns a relevance score (0.0 – 1.0) to each document.
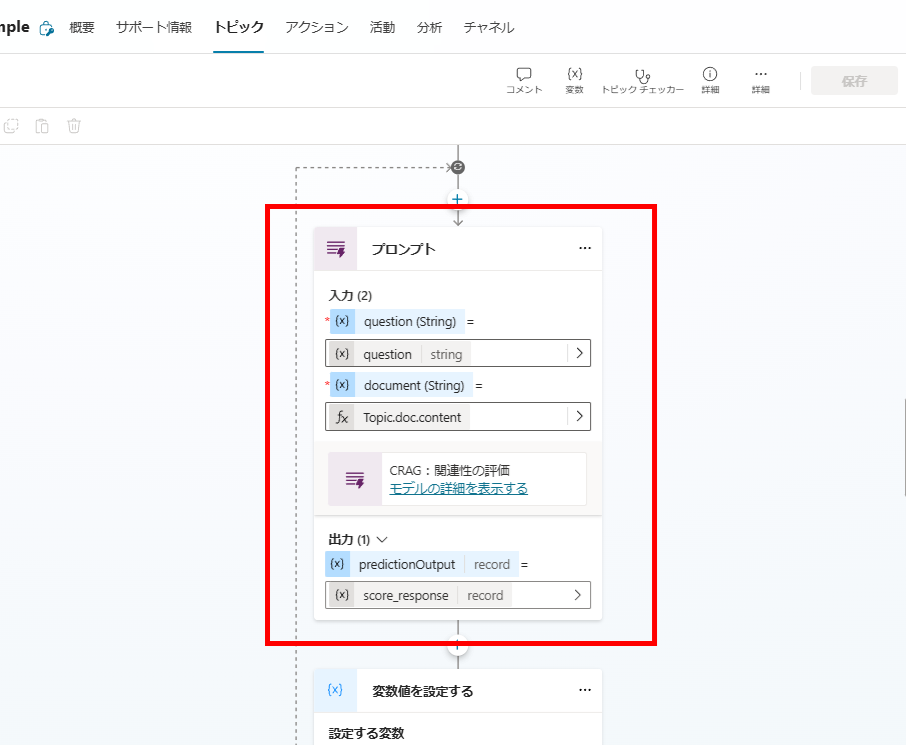
The scoring prompt uses strict criteria to ensure accuracy.
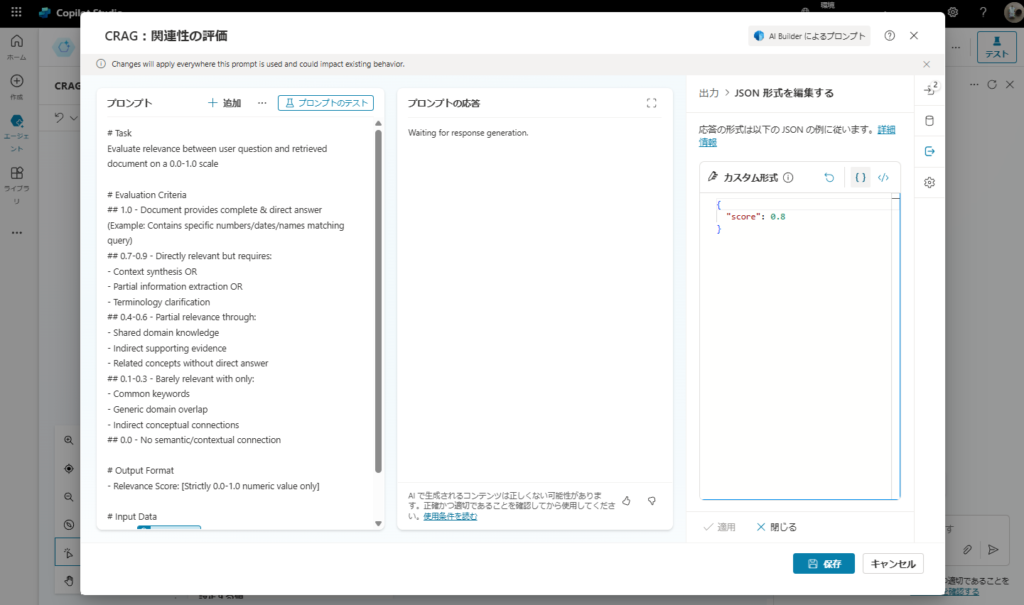
# Task
Evaluate relevance between user question and retrieved document on a 0.0-1.0 scale
# Evaluation Criteria
## 1.0 - Document provides complete & direct answer
## 0.7-0.9 - Directly relevant but requires synthesis
## 0.4-0.6 - Partial relevance (shared domain knowledge)
## 0.1-0.3 - Barely relevant (common keywords only)
## 0.0 - No semantic connection
# Output Format
- Relevance Score: [Strictly 0.0-1.0 numeric value only]
# Input Data
Query: {question}
Retrieved Document:
{document}
We append the calculated “Score” to each document, creating a structured Documents array.
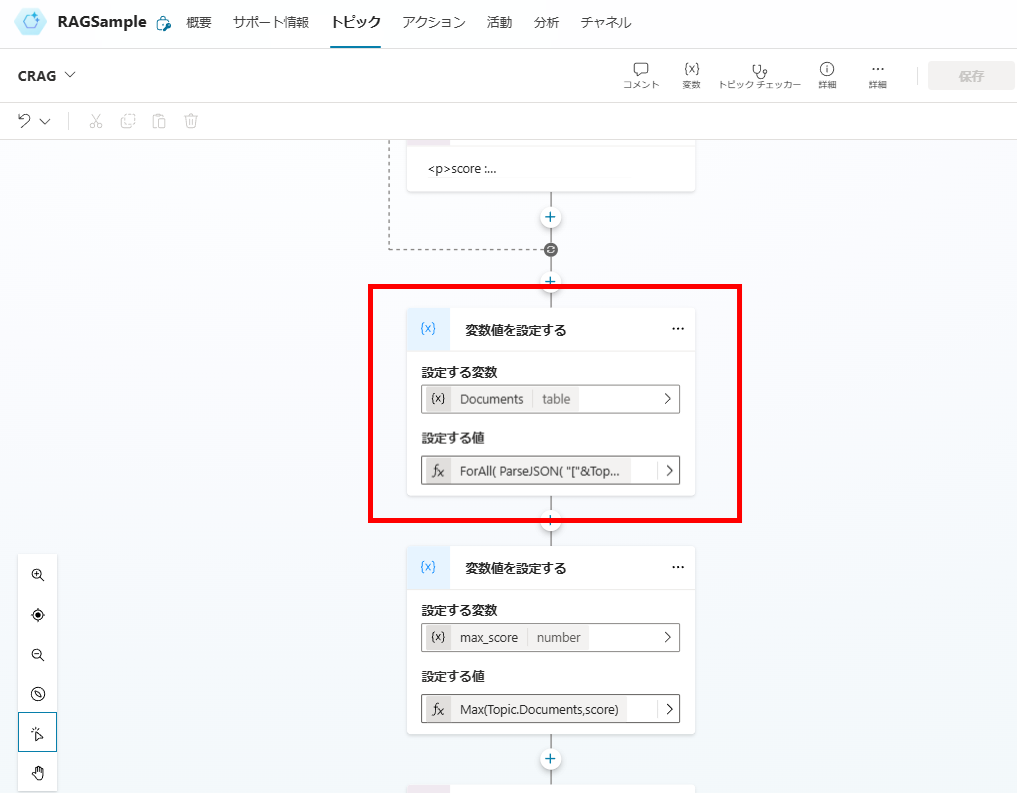
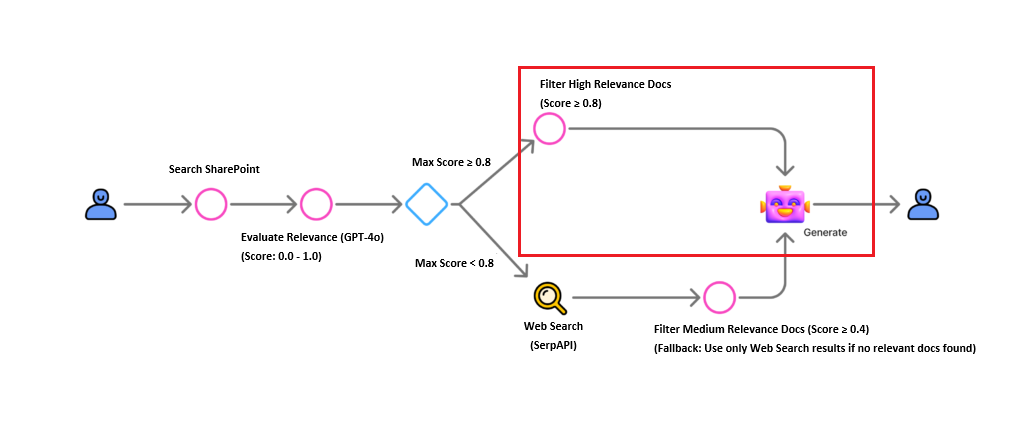
3. Conditional Logic Based on Relevance
We determine the next action based on the highest relevance score found.
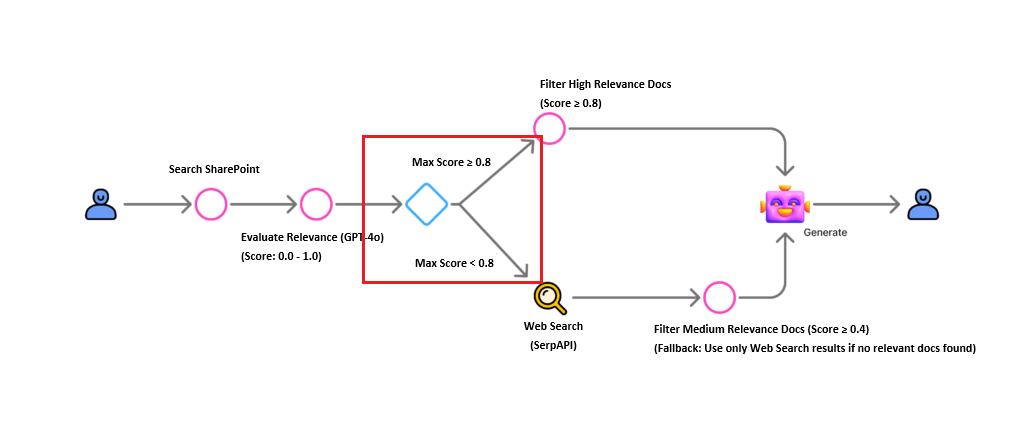
Using the Max() function, we identify the highest score in our dataset.
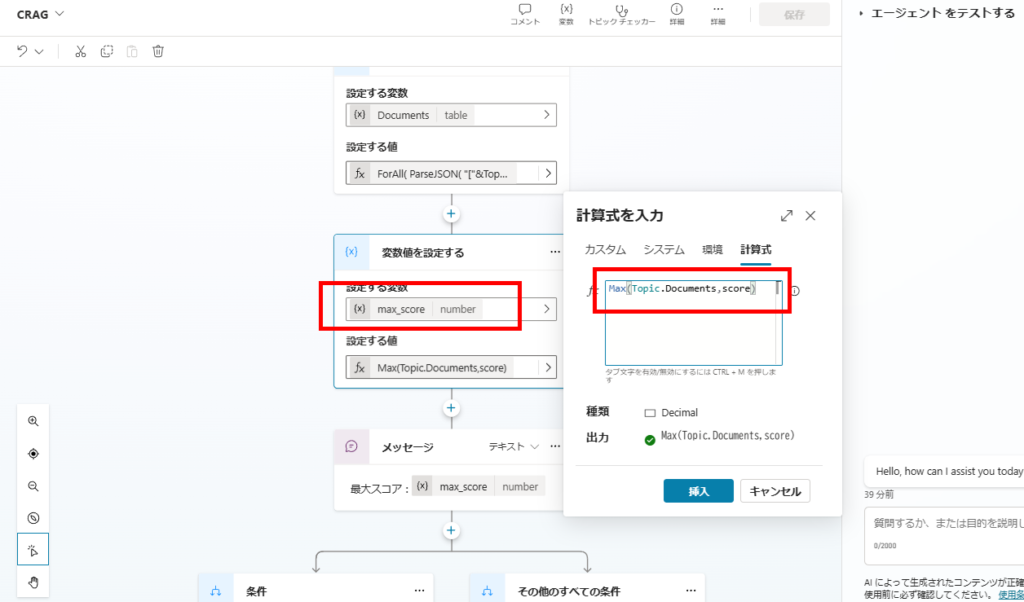
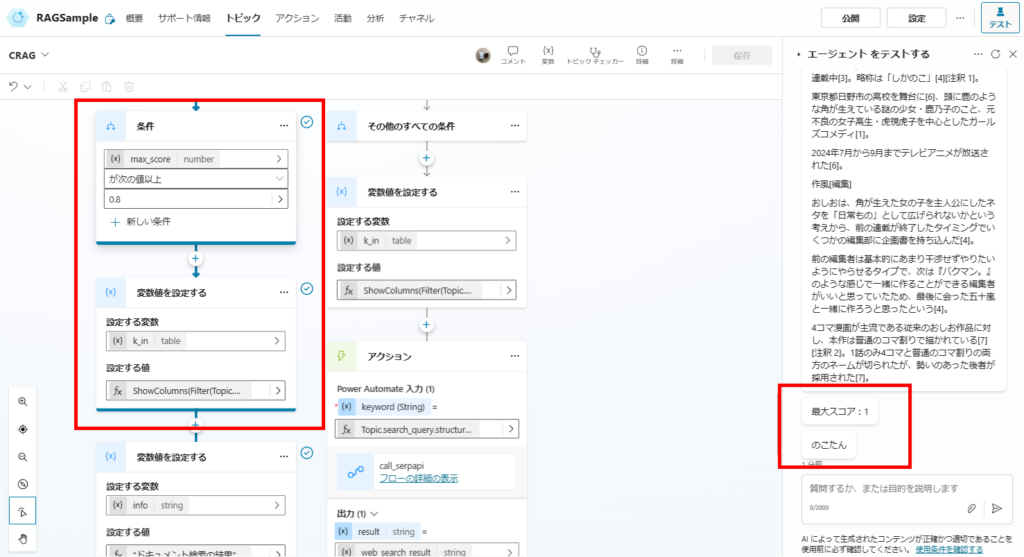
A condition node branches the flow: Is Max Score ≥ 0.8?
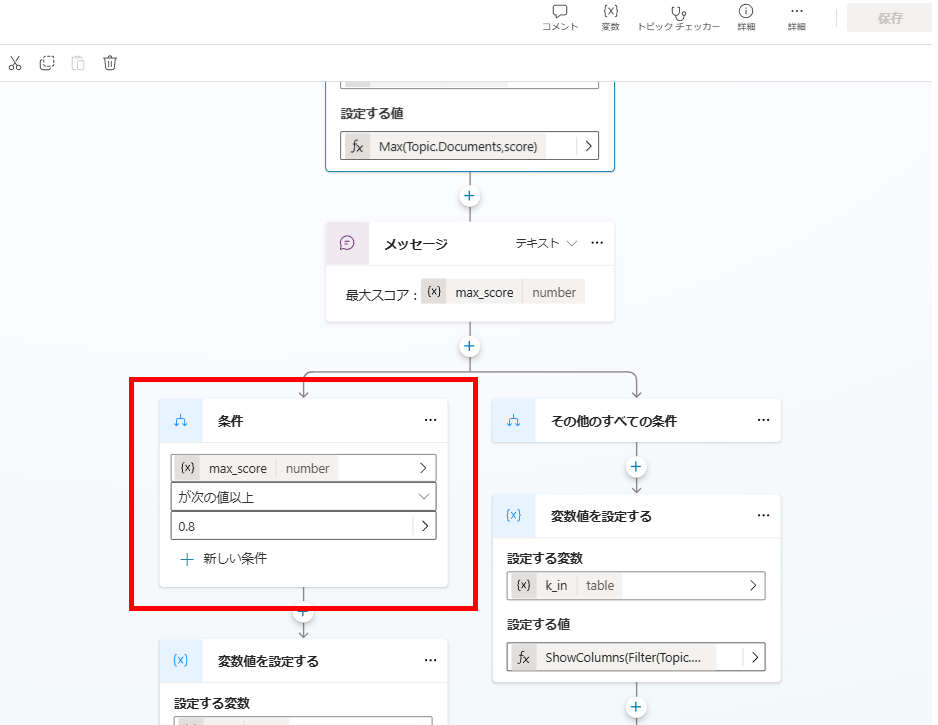
Case A: High Relevance (Score ≥ 0.8)
If highly relevant documents exist, we filter for them and generate the final answer directly.
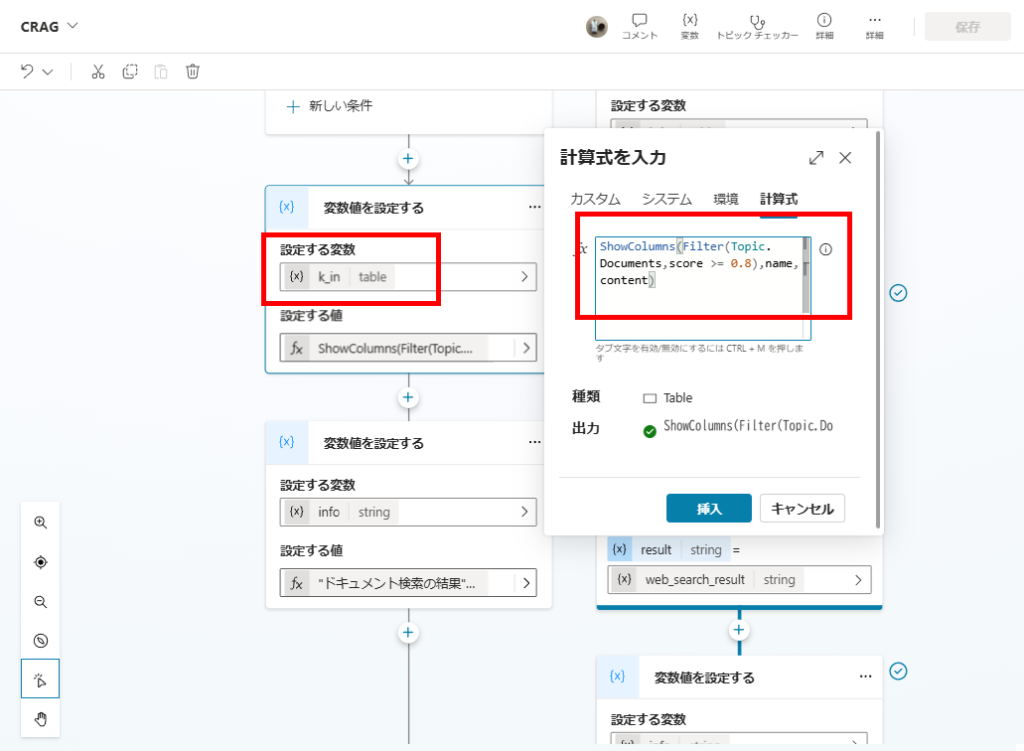
Filter the Documents array for items where Score >= 0.8 and store them in variable k_in.
Pass k_in to the generation prompt to produce the answer.
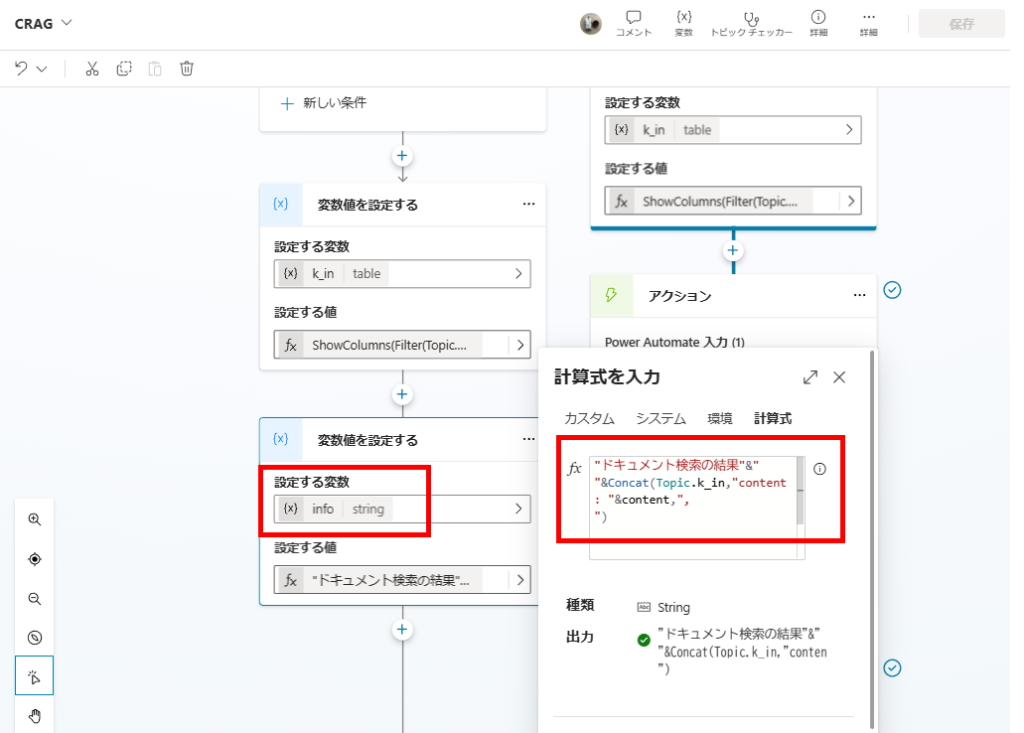
Case B: Low/Ambiguous Relevance (Score < 0.8)
If no perfect document is found, we trigger a web search fallback.
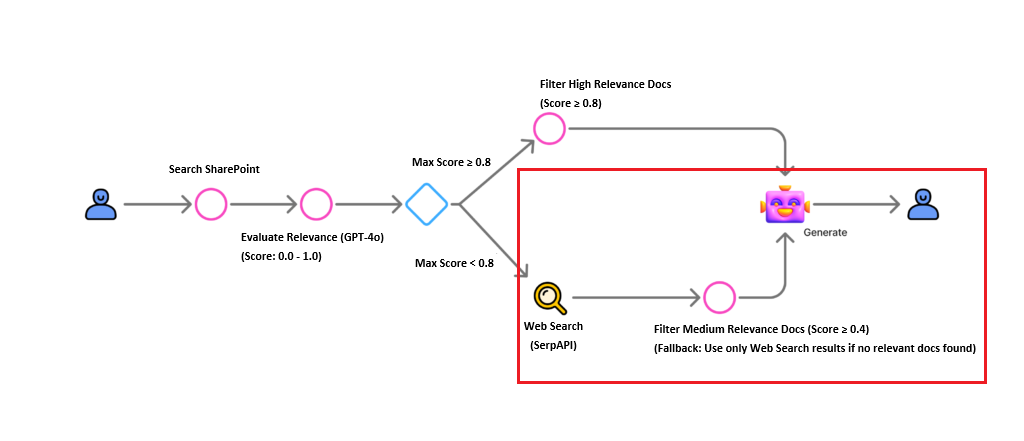
First, we attempt to salvage partially relevant documents (Score ≥ 0.4) into k_in.
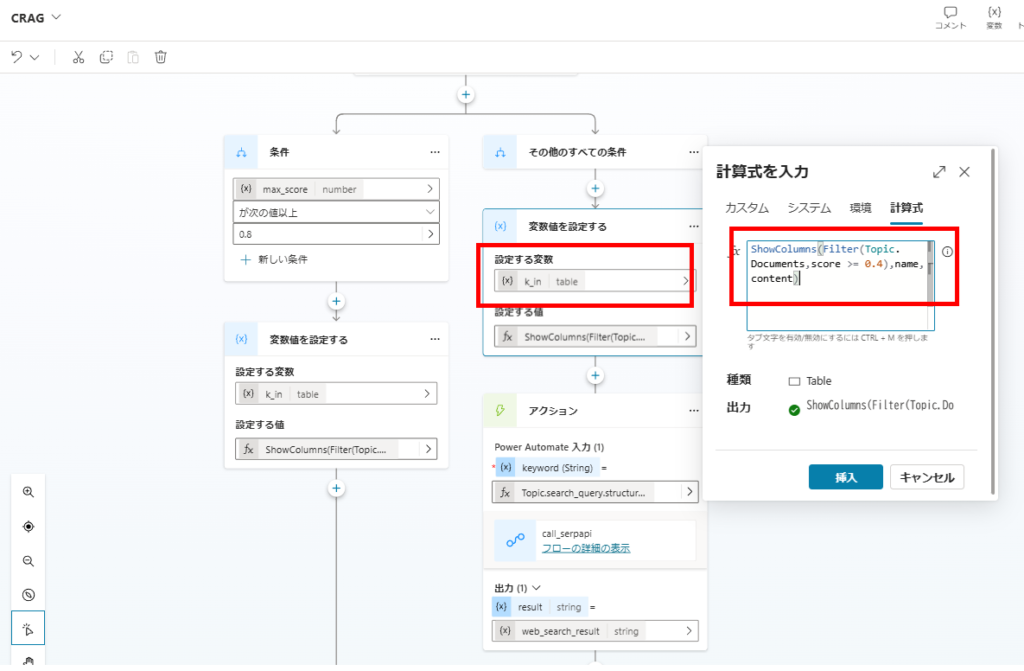
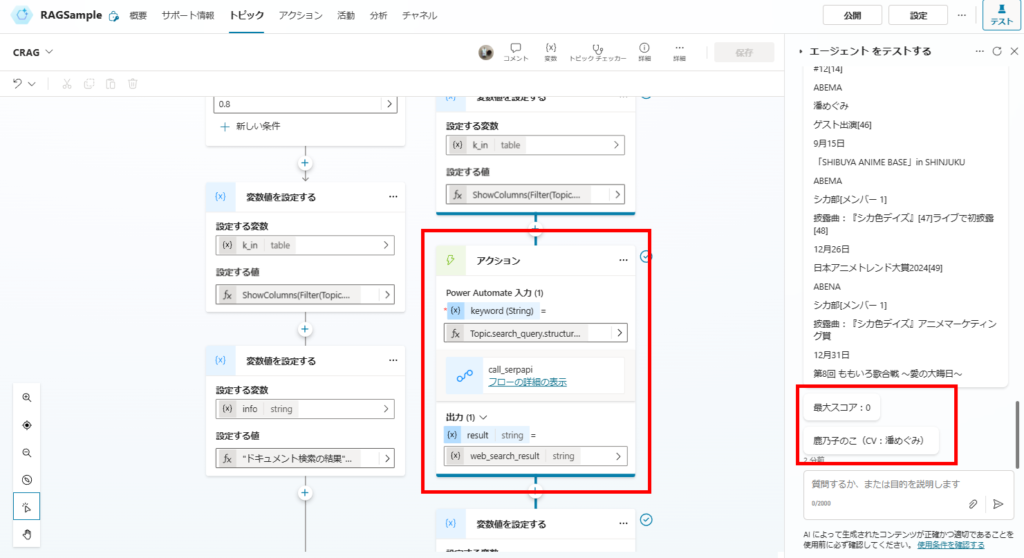
Next, we execute a web search using SerpAPI via Power Automate.
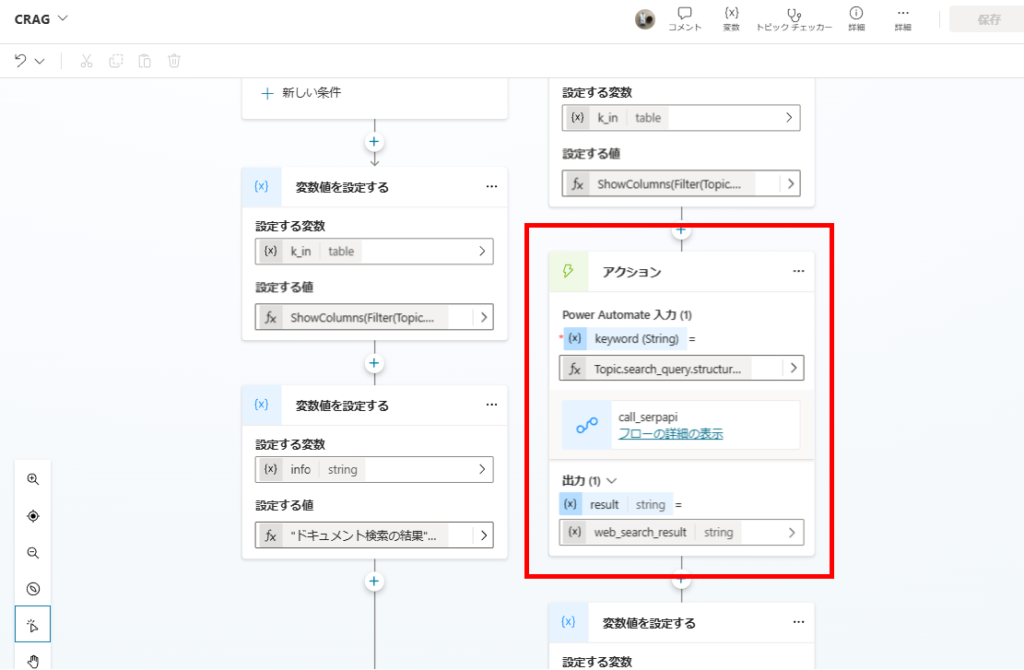
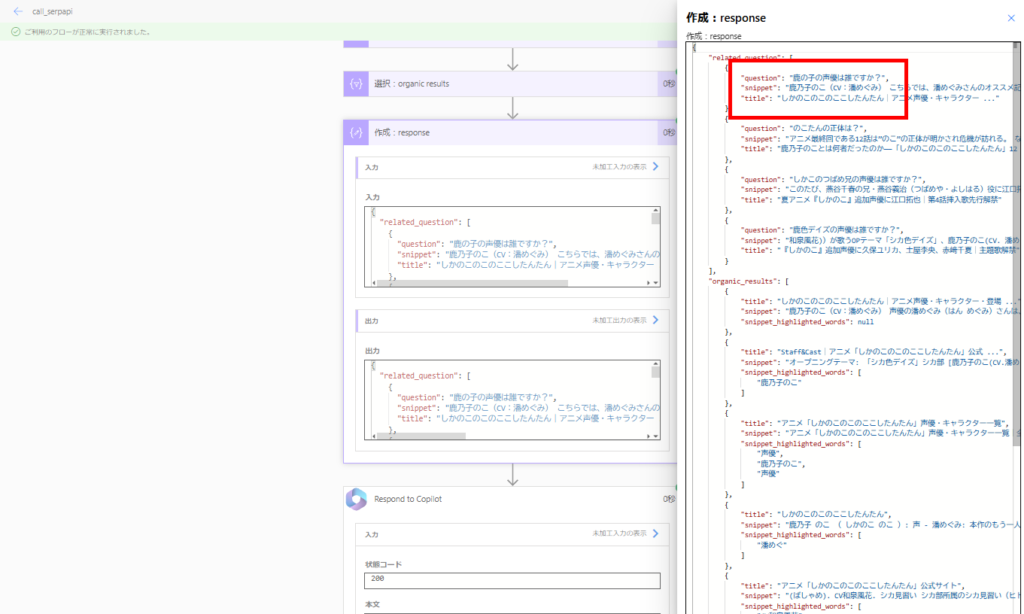
We utilize the related_question and organic_results fields from the SerpAPI response.
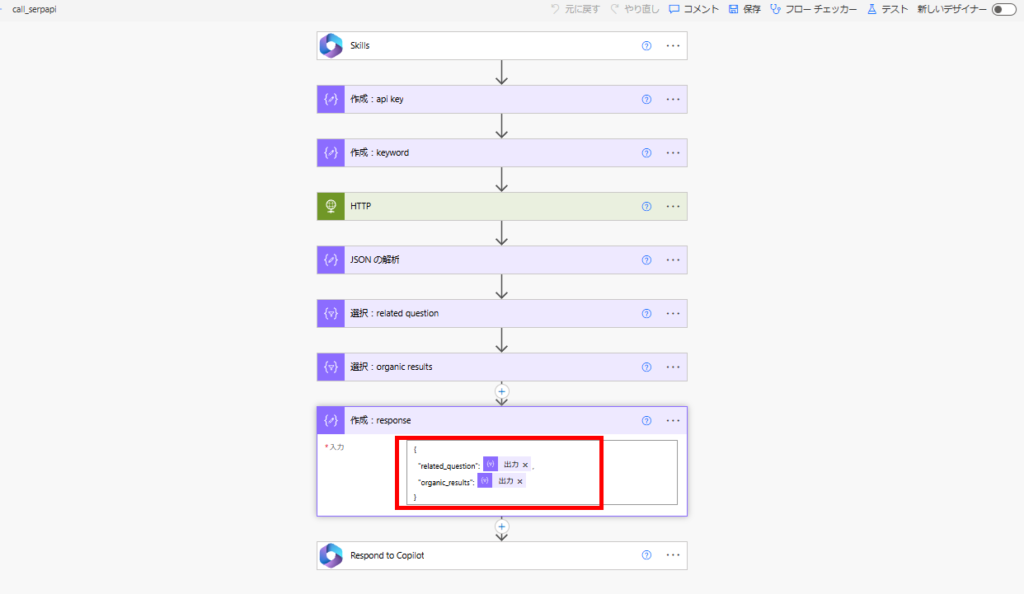
Finally, we combine both k_in (if any) and the web search results to generate the answer.
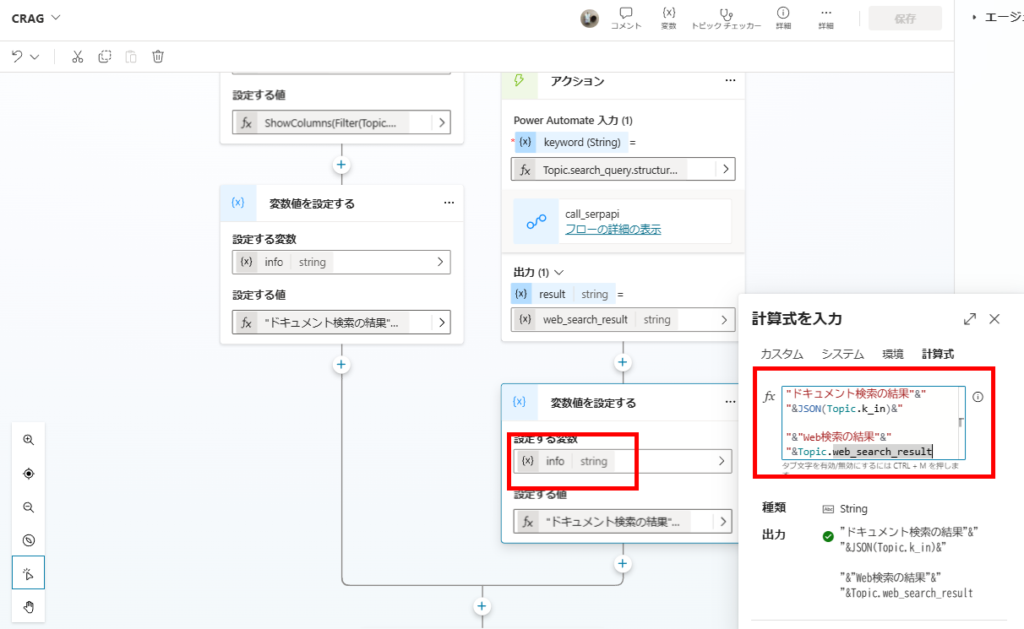
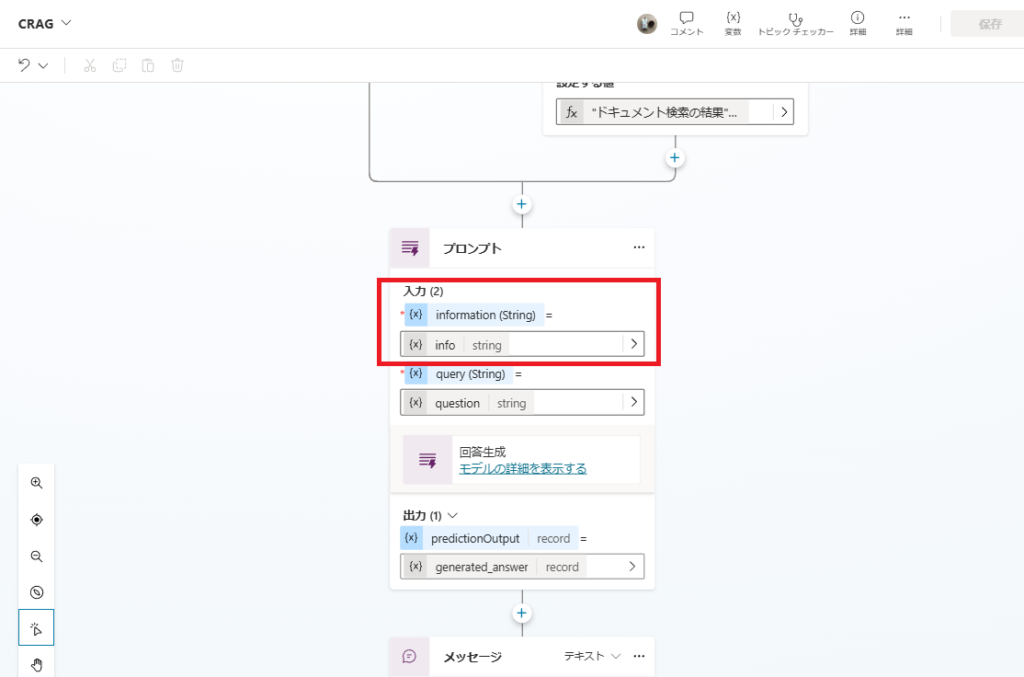
4. Final Answer Generation
The final prompt synthesizes the answer from the provided context.
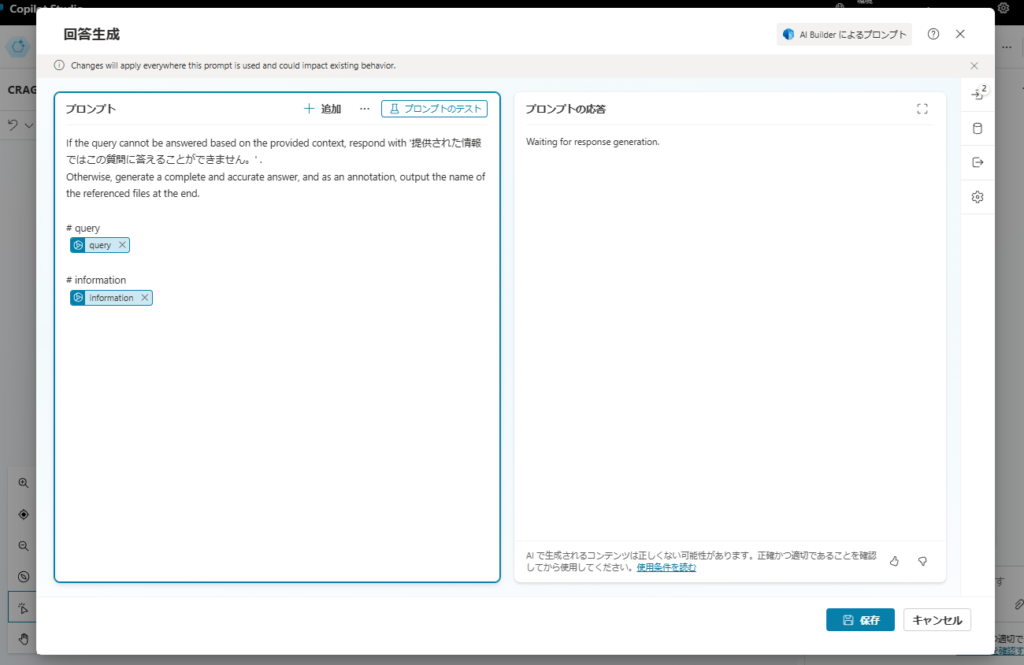
If the query cannot be answered based on the provided context, respond with 'The provided information is not sufficient to answer this question.'
Otherwise, generate a complete and accurate answer, and as an annotation, output the name of the referenced files at the end.
# query
{query}
# information
{information}
Testing & Results
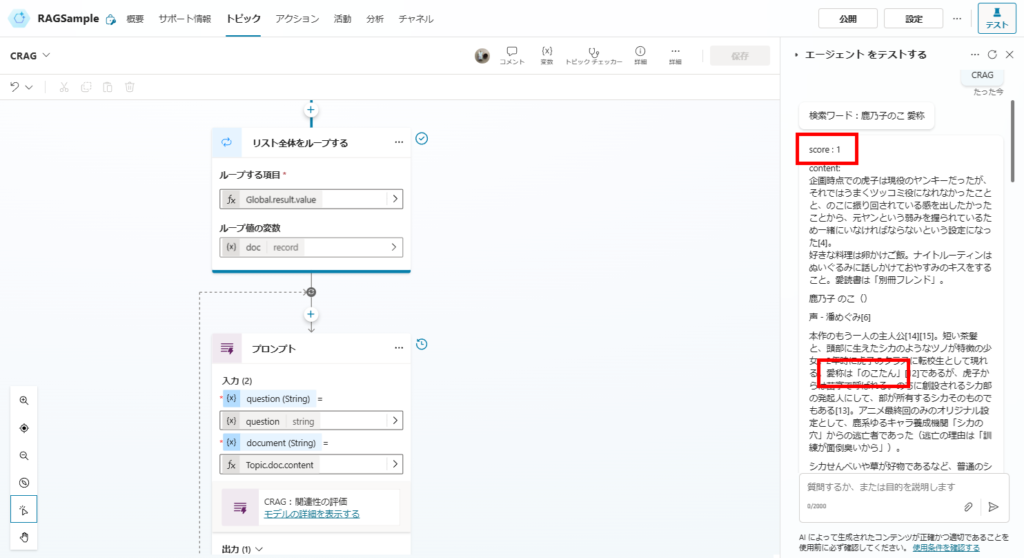
Test 1: Internal Knowledge Query
When asking a question covered by SharePoint documents, the system identifies a high-relevance document (Score: 1.0) and answers directly.
Test 2: External Knowledge Query
When asking a question NOT in SharePoint, the max relevance score is 0. The system correctly falls back to Web Search and provides an accurate answer from the internet.
This confirms that our CRAG implementation effectively reduces hallucinations by validating internal data and supplementing it with external sources when necessary.
コメント